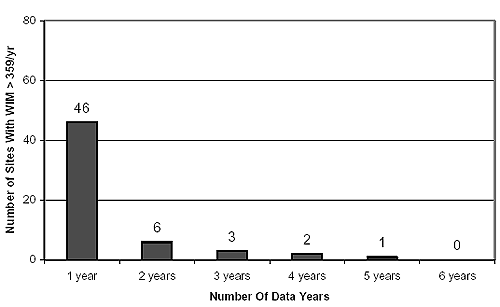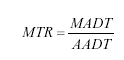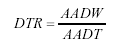U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-05-079
Date: May 2006 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Optimization of Traffic Data Collection for Specific Pavement Design ApplicationsChapter 4. LTPP Data AnalysisThe data necessary for filling the two knowledge gaps identified earlier were extracted from the LTPP database:
The following subsections present:
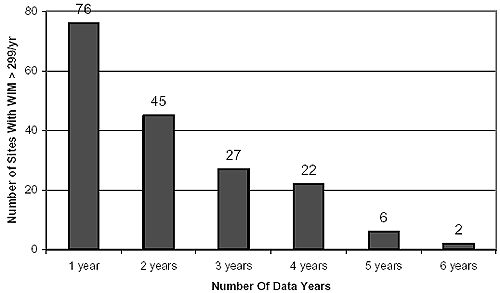
LTPP WIM Data ExtractedThe main criterion for selecting data from the LTPP database was the extent of WIM data coverage in terms of the total number of data days per year. A search of the LTPP database(16) was performed based on this criterion. Initially, a filter of 359 days per year or greater was selected (i.e., 2 percent of days per year missing). This resulted in a total of 58 sites, some involving multiple data years. To increase the number of sites available for analysis, a lower threshold filter was used involving WIM coverage of 299 days per year or greater (i.e., 20 percent of days per year missing). This resulted in a total of 178 sites, some involving multiple data years. The number of LTPP sites meeting these two criteria versus the number of data years available are plotted in figures 2 and 3, respectively. Figure 2, for example, suggests that 46 sites have more than 359 days per year of WIM data for 1 year; 6 sites do so for 2 years, and so on. Multiple years of data for the same site are advantageous because they allow for the establishment of traffic growth patterns. The data quality for these sites was deemed to be level E (i.e., the data had passed the quality control conducted by the State DOTs and the LTPP regional support contractor offices). To further ensure data quality, the LTPP quality assurance reports pertaining to these 178 sites were examined. They revealed no particular problems with any of them. These quality assurance reports were not appended here, but they are available on request. The highest resolution of traffic data necessary for simulating the scenarios in table 8 is daily summaries, which are not contained in Data Release; therefore, data had to be retrieved from the CTDB. It contains traffic data at five levels of resolution:
Given the highest resolution of daily data desired for simulating the 17 traffic scenarios, level 3 WIM data were extracted from the CTDB for the 178 WIM sites for the data years identified. The data fields extracted are described in table 10. The data was in Microsoft® Access format. It contained the daily number of axle passes by truck class, axle type, and load bin as it combined axle weight and vehicle classification information. Figure 2. LTPP sites with WIM data available for periods longer than 359 days per year.(16)
Figure 3. LTPP sites with WIM data available for periods longer than 299 days per year.(16)
Rationale For Selecting Sites For The Detailed Sensitivity AnalysisA number of these extended WIM data coverage LTPP sites were selected for the detailed sensitivity analysis of the NCHRP 1-37A design guide with respect to the traffic input obtained from the simulated traffic data collection scenarios (table 8). The remaining sites were used for obtaining the regional traffic data sets (i.e., vehicle classification and axle-load distribution estimates for the detailed sensitivity analysis sites). The following criteria were used for selecting sites for the detailed sensitivity analysis:
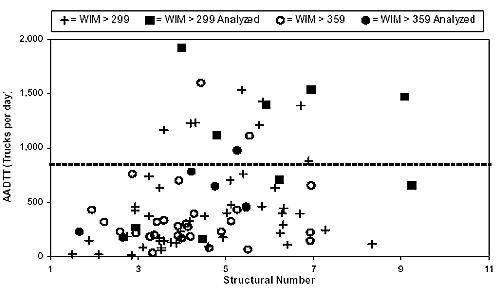
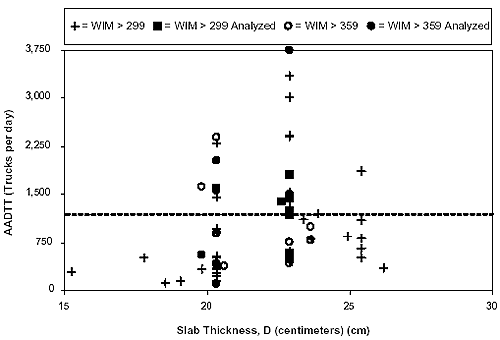
The latter was indexed by the structural number (SN) and the concrete slab thickness for flexible and rigid pavement sites, respectively. Figures 4 and 5 show the distribution of AADTT versus structural thickness for all of the extended-coverage WIM sites identified from the LTPP database for flexible and rigid pavements, respectively. For each pavement type, two AADTT intervals were identified. For flexible pavements, two truck traffic volumes were defined:
Figure 4. Flexible pavement site selection by AADTT and structural number.
Figure 5. Rigid pavement site selection by AADTT and slab thickness.
For rigid pavements, two truck traffic volumes were defined:
The final selection of sites for the detailed sensitivity analysis was carried out by identifying 5 to 10 sites in each AADTT interval. For each interval, the sites selected covered a range in AADTT, while satisfying the other two criteria listed earlier (i.e., highest possible WIM data coverage over multiple years). For rigid pavement selection, additional consideration was given to structural configuration (roughly half of the pavement sections selected was jointed and the other half was continuously reinforced). Background information on the sections selected for the detailed sensitivity analysis of the NCHRP 1-37A design guide is given in tables 11 and 12. These tables identify the years of extended WIM data coverage (i.e., 299 days per year or greater), the AADTT for the year selected for the detailed sensitivity analysis, and the structural thickness/configuration of the sites. The data for the remaining years were used to establish the truck traffic growth rate for these sites. Identifying Groups Of Sites For Obtaining Regional DataAs shown in table 8, the numerous traffic data collection scenarios needed for simulation involve representative regional traffic data; therefore, it was necessary to establish a formal process for developing representative regional traffic data for the detailed sensitivity analysis sites identified above (tables 11 and 12). This grouping needs to be carried out separately for establishing vehicle classification information and axle-load information (the second and fifth input components of the NCHRP 1-37A design guide, respectively, as described in table 6). It could be done subjectively using roadway functional class criteria, such as the ones shown in table 13. It is clearly better to do so using objective criteria, such as clustering techniques. As described in the literature review, clustering was introduced in the 2001 TMG (Appendix 2-b as the preferred technique for identifying sites with similar seasonal traffic volume distribution patterns.)(3) Clustering is used in this study to identify sites with similar vehicle classification distributions and axle-load distributions. As mentioned earlier, the vehicle classification and axle-load distributions in the NCHRP 1-37A design guide are input in the form of frequency distributions (percentage). As a result, there is no need to establish regional sites in terms of similar pavement loading, as is done for conventional TWRGs, nor it is necessary to use the rather outmoded ESAL concept for doing so (this is likely to influence future editions of the TMG). In terms of load distribution, regional clusters were identified with respect to tandem axles only because they are the most common in the traffic stream. It should be noted that a number of alternatives were considered, including the use of raw load distribution for all four-axle types and the load distribution of all four axle types weighed by their relative frequency in the traffic stream. Using the distribution of the tandem axles was only favored for its simplicity. Furthermore, in developing regional traffic data, clustering was done by State. Although there is no fundamental reason for partitioning the nationwide data, it better simulates the practice of individual DOTs that work primarily with their own data. A detailed description of the clustering technique can be found in statistical texts.(16) A brief overview of the method is given below and explained through an example involving the LTPP WIM sites in Washington State.
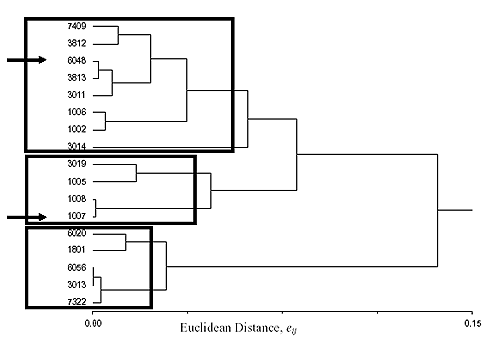
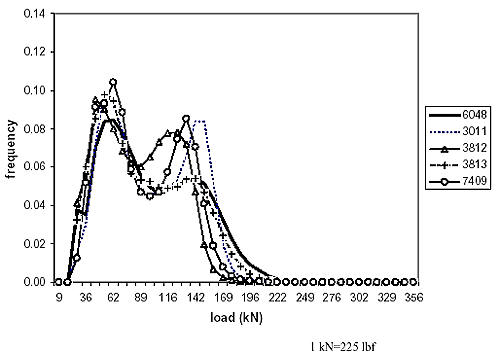
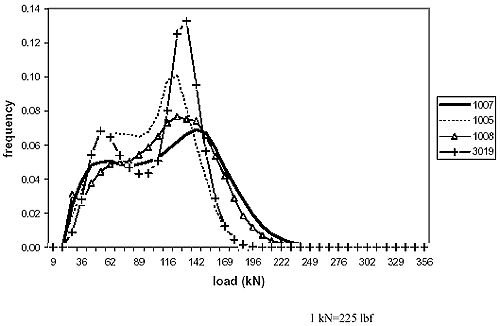
Clustering is a mathematical approach for establishing similarities between different objects. Objects are described by their attributes. For this particular example, the objects are the LTPP WIM sites identified in Washington State (the 17 that met the study criteria) and the attributes are the distribution of the load of tandem axles (40 load bins from 8.90 to 355.9 kN (2 to 80 thousand pounds force (kips)). In this particular example, the attributes need not be normalized because they are all frequencies adding up to 100 percent. The next step is to compute a dissimilarity coefficient matrix. For this purpose, the so-called Euclidean distance e is used, which is defined as the distance between attributes for each pair of objects. If there were only two attributes, i and j, and they were plotted in a Cartesian coordinate system, the Euclidean distance eij would be the linear distance between the two objects defined on this plot by their coordinates. For more than two attributes, a similar definition would apply, the difference being that this would be a multidimensional plot (40 dimensional in this example). The Euclidean matrix for the annual distribution of tandem-axle loads in Washington State LTPP sites is shown in table 14. A value of the coefficient eij close to 0.0 suggests a similarity between the pair of objects, while higher eij values suggest a significant difference between the pair of objects. The next step is to construct what is referred to as a clustering tree, where pairs of similar objects are successively grouped together and compared with the remaining objects in order of increasing eij. The clustering tree for this example is presented in table 15 and plotted graphically in figure 6. This clustering method is referred to as Ward's Minimum Variance Method. All of these calculations were carried out using an add-on function to Microsoft Excel found in the statistiXL® library.(17) Figure 6 allows identification of groups of WIM sites in Washington State with similar distributions of tandem-axle loads, given a selected value of the Euclidean distance, and therefore, a level of acceptable dissimilarity. Three clusters were identified, assuming an eij value of 0.07. For the two WIM sites to be analyzed (6048 and 1007 as indicated by arrows), the selected groups for obtaining regional WIM data are identified by the two uppermost squares in figure 6. Figures 7 and 8 show the frequency distributions of tandem-axle loads for these two groups and illustrate the distinct difference in the patterns between the two groups of WIM sites identified. For the LTPP sites selected for traffic scenario simulation, tables representing clustering trees by State are presented in Appendix B. This includes clusters with respect to the annual average tandem-axle load distributions and clusters with respect to the annual average truck classification and distributions (i.e., FHWA classes 4 through 13). The actual LTPP sites finally selected for obtaining regional AVC and WIM data are summarized in tables 16 and 17, respectively. The highlighted sites in these two tables are the ones used in the detailed sensitivity analysis of the NCHRP 1-37A design guide, while data from the other sites are used to estimate regional vehicle classification and axle-load distributions. As an example, the regional vehicle classification data for site 182008 were estimated as the average of the vehicle classification distributions for sites 181037, 183031, and 184042. For sites that exhibit no similarities with others (e.g., site 091803), the statewide average was assumed to be representative of the regional data.
Figure 6. Annual distributions of tandem-axle loads, Washington State LTPP sites.
Figure 7. Tandem-axle load distributions for the cluster of Washington State LTPP site 6048.
Figure 8. Tandem-axle load distributions for the cluster of Washington State LTPP site 1007.
Note: The 30 sites used for the detailed sensitivity analysis are shaded.
Note: The 30 sites used for the detailed sensitivity analysis are shaded. Simulating Traffic Data Collection ScenariosAs described in the literature review, obtaining traffic input to the NCHRP 1-37A design guide from short-term traffic samples involves considerable calculations in factoring the site-specific data available using representative regional or national vehicle distribution and axle-load distributions. TrafLoad(13) could be used to carry out these calculations; however, it accepts as input raw data (e.g., card-4 and card-7) and therefore, was not directly applicable to the daily summary data format used in this study. More important, TrafLoad could not be used to analyze all of the possible combinations of data used in simulating short-term scenarios from extended-coverage WIM data (1 month/season of data involves 34 = 81 combinations of months, as described later). Therefore, it was decided to develop customized software for computing the traffic data input to the NCHRP 1-37A design guide. The software developed is written in Microsoft®Visual Basic®. It reads daily traffic data summaries from the Microsoft Access database extracted from the CTDB and computes the traffic input elements to the NCHRP 1-37A design guide following the procedures described in the 2001 TMG.(3) Furthermore, it adopts the traffic ratio approach in factoring short-term counts, as described by NCHRP 1-39.(13) Accordingly, equations 15, 16, and 17 for factor ratios are used. (The subscripts i for vehicle class and l for direction were dropped for brevity.) (15)
Where:
For each of the traffic data collection scenarios, the software computes the mean and the standard deviation (SD) for each of the NCHRP 1-37A design guide traffic data input elements outlined in table 6. The methodology used for doing so follows. Scenario 1-0: Site-Specific Continuous WIM DataThis scenario represents the most complete traffic data set for generating input to the NCHRP 1-37A design guide, and for this reason, it is defined as the truth in traffic data. For the 30 sites analyzed, WIM data coverage ranged from more than 299 days per year to more than 359 days per year. Following is an explanation of how the five traffic data input components to the NCHRP 1-37A design guide (refer to table 6) were computed:
The procedure described above accommodates WIM traffic data sets with missing data days. For some of the WIM sites that have the largest number of missing days (i.e., 299 days of WIM data per year or more), additional assumptions had to be made:
Scenario 1-1: Site-Specific WIM Data for 1 Month/4 SeasonsThis scenario involves WIM data that cover 1 month in each of 4 seasons. It is simulated from the continuous WIM data set of the 30 sites selected and is carried out by computing all of the necessary traffic input to the NCHRP 1-37A design guide from random combinations of sets of 4 months, each from a different season (a maximum of 81 combinations is possible). Only months with more than 25 days of data were considered for this analysis. The challenge in simulating this scenario is that the traffic volume by truck class is not known for all months of the year. All that is known for the site is the volume for 4 months of the year. The following paragraphs describe the methodology used in obtaining each of the five traffic data components input to the NCHRP 1-37A design guide (table 6). Component 3 of the NCHRP 1-37A Design Guide Input (MAFs):There are a number of alternative algorithms for computing traffic volumes and, as a result, MAFs by vehicle classification for the months considered missing. The one selected for this study uses the average regional MAF values for all truck classes to estimate truck volumes by class for the missing months. This algorithm is explained in the following example, and it is demonstrated in table 18.
Consider that for a given truck class, daily traffic volumes (VOL) are available only for January, April, July, and October (they add up to a volume of 4,150 vehicles). Given the average regional MAF values above, compute the sum of them for the available months (i.e., 3.94). This suggests that the sum of the regional MAF values for the 8 missing months is 8.06 (=12-3.94), which gives a total volume of 8,489 (= 4,150x8.06/3.94) for these months. This, in turn, allows estimation of the traffic volume of the missing months (e.g., February volume is computed as 8,489x0.9/8.06 and so on). Note that this approach preserves the traffic volume for the available months. The group of sites used for obtaining the regional MAF data was identified as the agency-specific cluster that exhibited a similar truck classification pattern as the site under consideration (truck classification clusters are presented in Appendix B and summarized in table 16). This was deemed to be reasonable compromise between using agencywide average MAF data for all truck classes and MAF cluster data for individual truck classes. Furthermore, it was practical to implement since the monthly vehicle classification distributions are relatively stable (table 19), and thus identifying a cluster from 4 months of traffic data is realistic.
Components 1, 2, and 5 of the NCHRP 1-37A Design Guide Input (AADTT, Truck Class, and Axle-Load Distribution):Having established the volumes by truck class for the missing months, the algorithm used for obtaining traffic data input components 1, 2, and 5 was identical to that for scenario 1-0. Component 4 of the NCHRP 1-37A Design Guide Input (Number of Axles per Truck):The number of axles by axle configuration and truck class was assumed to be constant and equal to each statewide average for the sites analyzed. This assumption is justified considering that the number of axles for the most common truck classes (classes 5 and 9) is relatively constant. Tables 20 and 21 show the number of single and tandem axles per vehicle for the Washington State sites analyzed. It can be seen that the number of single and tandem axles for vehicle classes 5 and 9 varies only slightly between sites. This is not the case for vehicle classes 7 and 11; however, they account for less than 4 percent of the total truck volumes. Another reason for this assumption was that the number of axles per vehicle type (i.e., 4 by 10 matrix) had to be input manually to the NCHRP 1-37A design guide software, and therefore, assuming it to be constant for each agency, significantly reduced the data input effort.
Scenario 1-2: Site-Specific WIM Data for 1 Week/SeasonThis scenario was simulated in a manner similar to the one described under scenario 1-1. The difference was that only 1 week per season of WIM data was considered available. For each season, a week was selected at random, after excluding the dates involving national holidays and those having incomplete data. This simply yielded a higher number of combinations to be simulated (i.e., depending on data coverage, up to 20,736 combinations). Each week was assumed to be representative of the entire month. The handling of the remaining elements of the NCHRP 1-37A design guide input was identical to that described under scenario 1-1. Scenario 2-0: Continuous Site-Specific AVC Data and Regional WIM DataThis scenario used only the vehicle classification information that is available from the 30 WIM sites being analyzed. NCHRP 1-37A design guide inputs 1, 2, and 3 were obtained in an identical manner as done for scenario 1-0. For input 4, the number of axles by configuration and vehicle class, the agencywide average was used for reasons explained earlier. Input 5, which uses the load frequency distribution by axle configuration, had to be estimated from regional WIM data. In doing so, it was assumed that although there are no site-specific WIM data, there is sufficient qualitative information for truck weights for the site to allow classification of it into one of the axle-load clusters determined within a particular agency. As a result, input 5 was obtained from the average WIM data of the appropriate cluster, rather than from agencywide WIM data. Scenario 2-1: Site-Specific AVC Data for 1 Month/Season and Regional WIM DataThis scenario was simulated in a manner similar to that for scenario 1-1. The difference was that traffic data input 5, the load distribution by axle configuration, was obtained from regional WIM data as described under scenario 2-0. Scenario 2-2: Site-Specific AVC Data for 1 Week/Season and Regional WIM DataThis scenario was simulated in a manner similar to that for scenario 1-2. The difference was that traffic data input 5, the load distribution by axle configuration, was obtained from regional WIM data as described under scenario 2-0. Scenario 2-3: Site-Specific AVC Data for 1 Week/Year and Regional WIM DataThis scenario was simulated by assuming that the week of data considered available is representative of the month to which it belongs. After excluding those involving national holidays and those having incomplete data, weeks were selected at random, and subsequently, in traffic data input 3, the MAFs were estimated from the regional vehicle classification cluster corresponding to the site in question. Traffic data inputs 1, 2, and 4 were also estimated as per scenario 1-1. Finally, traffic data element 5, the load distributions by axle type, were obtained from regional WIM data as described under scenario 2-0. Scenario 3-0: Continuous Site-Specific ATR Data, Regional AVC Data, and Regional WIM DataThis scenario consists of continuous site-specific vehicle counts for an entire year combined with regional AVC and regional WIM data. These vehicle counts include vehicle classes 1 through 3: motorcycles, passenger cars, and light four-tire trucks. Although no site-specific vehicle classification or load information is available, it was assumed that there exists qualitative information to assign the site correctly to one of the AVC clusters and one of the WIM clusters developed for the agencies analyzed; therefore, the percentage of trucks at the site (classes 4 through 13) was assumed to be equal to the average of the percentage of trucks at the sites that belong to the actual AVC cluster for this site. This allowed calculation of AADTT according to the method described under scenario 1-0. Traffic data input 2 was obtained as the average of the vehicle classification distribution for the sites that belong to the actual AVC cluster for the site. Similarly, traffic data input 3 was obtained as the average of the MAFs for the sites that belong to the actual AVC cluster for the site. Traffic data input 4, the number of axles by type and vehicle class, was assumed to be equal to the statewide average for the reasons described under scenario 1-1. Traffic data input 5, the load distribution by axle configuration, was obtained as the average of the data for the actual WIM cluster to which the site belongs. It should be noted that this scenario results in a far lower variation in traffic data input than most of the scenarios described earlier because it relies on continuous regional data for the majority of the input. Scenario 3-1: Site-Specific ATR Data for 1 Week/Season, Regional AVC Data, and Regional WIM DataThis scenario was simulated in a manner similar to scenario 3-0. The only difference is that vehicle volume data are considered known only for 1 month for each of 4 seasons. Traffic data input 2, 3, 4, and 5 were obtained in a similar manner to scenario 3-0. Traffic data input 1, the AADTT, was computed as described under scenario 1-1. Scenario 4-0: Continuous Site-Specific ATR Data, Regional AVC Data, and National WIM DataThis scenario is similar to scenario 3-0. The only difference was that the axle-load information from the WIM cluster was replaced with information from national average WIM data. The latter was assumed to be equal to the default axle-load distributions embedded into the NCHRP 1-37A design guide software. This assumption affected only traffic data input 5, the load distribution by axle configuration. Scenario 4-1: Site-Specific ATR Data for 1 Week/Season, Regional AVC Data, and National WIM DataThis scenario was simulated in a manner similar to scenario 3-1. The difference was that the axle-load information from the WIM cluster was replaced with information from national average WIM data. The latter was assumed to be equal to the default axle-load distributions embedded into the NCHRP 1-37A design guide software. Scenario 4-2: Site-Specific ATR Data for 1 Week/Year, Regional AVC Data, and National WIM DataThis scenario is a variation of scenario 4-1, where only a single week of data is available per year. As in scenario 2-3, 1 week was selected at random after excluding those weeks that involved national holidays or incomplete traffic data. This week was assumed to be representative of the entire year. As in scenario 3-0, regional AVC cluster data were used to compute percentage of trucks and average MAF values were used to obtain the traffic volumes by month and truck class. National WIM data (the default values in the NCHRP 1-37A design guide software) were used for traffic data input 5. Scenario 4-3: Site-Specific ATR Data for 1 Weekday Plus 1 Weekend/Year, Regional AVC Data, and National WIM DataThis scenario involves ATR counts from 1 weekday and 1 weekend day. Traffic volumes on these days were weighted by 5 and 2, respectively, to compute weekly traffic volumes. All weeks that did not involve holidays or missing data were considered at random under this scenario. Subsequently, all traffic data input elements were computed as described under scenario 4-2. Scenarios 4-4 through 4-7: Various-Coverage, Site-Specific ATR Data, National AVC Data, and National WIM DataThese scenarios are essentially identical to scenarios 4-0, 4-1, 4-2, and 4-3, respectively. The only difference is that traffic data inputs 2 and 3 were not computed from the regional AVC data, but rather from national data. For the latter, the default vehicle classification values embedded into the NCHRP 1-37A design guide were used. In doing so, the default classification distribution for truck traffic class (TTC) type 1 was arbitrarily selected and described as a major single-trailer truck route (i.e., predominantly class 9 trucks). The default MAF values embedded into the NCHRP 1-37A design guide were 1.00 for all months and vehicle classes. For each time coverage in site-specific ATR data, the method used for computing each of the traffic data input elements to the NCHRP 1-37A design guide was described earlier. Estimating Traffic InputThe preceding discussion documents in detail the methodology and assumptions used in obtaining each of the five traffic data input elements to the NCHRP 1-37A design guide (table 6) for each of the 17 traffic data collection scenarios considered (table 8). A summary of the source of data used in computing each traffic data input element to the NCHRP 1-37A design guide is given in table 22.
Table 23 shows the number of possible time-coverage combinations analyzed for each scenario. Obviously, the continuous data coverage scenarios (i.e., scenarios 1-0, 2-0, 3-0, 4-0, and 4-4) involve only a single time-coverage combination and, as a result, yield singular estimates of the traffic data input elements of the NCHRP 1-37A design guide (table 6). On the other hand, the discontinuous scenarios yield one set of traffic data input elements per data coverage combination. Statistics for this traffic data input were computed and their range was established as a function of the desired level of confidence.
For each confidence level, NCHRP 1-37A design guide simulations for the discontinuous time-coverage scenarios were conducted by considering the lowest percentile for all traffic input elements simultaneously (i.e., 1, 2, 3, and 5 as identified in table 6). The reason for considering traffic underprediction as critical is because it results in pavement designs that are thinner than required, which, in turn, would fail prematurely. The reason for specifying the lowest percentile of all traffic input simultaneously is because it allows computation of the statistical maximum error in pavement life predictions given a confidence level. As a result, it reflects the confidence that this level of error will not be exceeded, which, in turn, is the reliability in the pavement design process. In performing these NCHRP 1-37A design guide simulations, it was decided to keep the traffic growth rate constant for all vehicle classes (4 percent annually) to ensure comparable results between sites. The effect of the actual traffic growth rate on pavement-performance predictions for each site was studied separately and is detailed in Chapter 5 of this report.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||