U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-04-080
Date: September 2004 |
||||||||||||||||||||||||||||||||
Software Reliability: A Federal Highway Administration Preliminary HandbookPDF Version (697 KB)
PDF files can be viewed with the Acrobat® Reader® Chapter 6: WrappingThis chapter:
The following simple examples provide some context for the framework. IntroductionA wrapping for a piece of software is additional information that the software can use to answer questions about itself. The concept of wrapping was originally developed in National Aeronautics and Space Administration- (NASA) sponsored work on large systems.(6) An intended application of wrapping was to allow software to describe its function to make it easier to call the right function in a large software project. Wrapping also appears in Java in the form of the "instanceof" relation and the reflect package. These facilities allow objects to report on their contents and class membership. Applied to software correctness, wrapping is a technique that uses a modified version of a piece of software to compute its own correctness. To wrap a program P used in system S with a requirement R on P:
Wrapping has several different V&V applications:
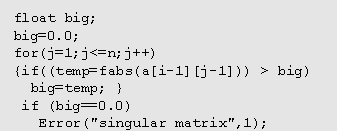
Several examples follow.(3) The Matrix InverseThe matrix inverse is a troublesome computation for matrices that are close to being singular. Except by using the theory of the application domain, there is no completely reliable way, to distinguish between:
Particular inverse functions work well for some matrices but break down when the input matrix becomes too ill-conditioned for the function. As an example, researchers have observed that several standard math packages computed an inverse for the following singular matrix:
Problems with the matrix inverse can be due either to numerical roundoff errors or to an underlying problem in the computer code. One of the math packages that has a problem with this matrix is Numerical Recipes in C.(7) The code segment that seems to cause the problem is:
This is the only point in the matrix inverse function that tries to detect singular matrices. It apparently fails because it is possible for both >0 and == 0 to fail for very small positive numbers (something that cannot happen in abstract mathematics of the real numbers). For reasons like this, it is considered good practice in writing numerical software to avoid strict equality tests with 0 and instead to write a test like: Where EPSILON is some number chosen to catch very small numbers that are more likely due to roundoff errors than legitimate results of numerical computations. However, no choice of EPSILON truly can separate actual and false inverses all the time. So instead:
Where:
Note that wrapped_inverse:
As a result, the caller of wrapped_inverse always knows whether the computed inverse really works as an inverse. Wrapping the Integer FactorialAs another example of wrapping, wrap the factorial in C. This function is shown below:
The problem is that:
A run of this program illustrates the problem:
To solve this program, create a wrapped version of the factorial:
This function has the same arguments and returns the same values as fact. However, it uses a floating point version of the factorial, fact, as a comparison to check for integer overflow. It returns the Boolean result of whether overflow occurred to the calling context of wrapped_fact using the call-by reference to flag, written here as C. The function ffact can be encoded by syntactic transformations on fact, e.g., changing int parameters to float. When the wrapped factorial is run, the error is detected: Inside wrapped_fact, arg = 8, *flag = 0 The double computation of fact, once integer and once real, can be improved in the following version of wrapped_fact. This version detects a discrepancy between integer and float computations and aborts at the earliest possible step.
Although the last definition of wrapped_fact is more efficient, it is more perilous. The type cast to float is needed. Otherwise, is integer multiplication in C, and the overflow occurs in both the value of fn_result and float_fn_result. The more efficient wrapping requires a more detailed knowledge of C arithmetic. The final code segment illustrates how passed-back correctness information can be used to control the calling context of a wrapped function. The following example driver tries an increasing set of factorials determined by the user. However, it quits as soon as an error as reported by the Boolean error flag occurs in any factorial.
In turn, this function returns a success value that can control its calling context:
The complete output of the above source code is listed in appendix A. Limitations of WrappingWrapping, at least as shown in the examples, where wrapping code is placed directly in the source code, has the following limitations:
Wrapping with Executable SpecificationsTo overcome the wrapping limitations caused by writing wrapping code directly in the source, write the specifications in a more declarative but computer-executable form, as is done in expert systems. This:
Then call the wrapping code external to the wrapped program, and apply the wrapping to files of inputs and outputs of the target program. This allows wrapping to be used even if source code is not available. The particular form for the specification knowledge base that will be used is a set of decision trees. This knowledge representation and the software for using it are discussed below. Knowledge Representation of SpecificationsDecision trees are useful in formalizing specifications, because:
When decision trees are used to check the results of a computer program, the decision tree returns a Boolean value: true if the decision tree is satisfied, and false if not. The inputs to and outputs from the program are used as values of variables referred to in the decision tree. The rules for computing the Boolean value of the decision tree are listed in the section below. Decision Tree Nodes for Representing Specifications
An example decision tree for part of the IHSDM design speed module appears later in this chapter. Deriving Useful SpecificationsGood specifications are important in creating reliable software; but specifications are notoriously incomplete and vague. SpecChek helps create more complete, precise specifications because it lets users incrementally develop and test specifications. Use SpecChek with the following plan to create precise, complete, and enforceable specifications for software projects:
Translating Informal Specifications into Decision TreesTranslate informal specifications by applying the following set of transformational rules to a partially translated specification, until the informal specification is completely translated into a decision tree. To represent the partially finished translation, the above decision tree specification will be modified to allow each node to have a special text subnode. The contents of the text node will be the part of the informal specification that is relevant to a decision tree node, and have not yet been translated into explicit decision tree nodes. A node with a text subnode will be considered to be satisfied if the satisfaction properties stated above are satisfied and the contents of the text node are satisfied. With these conventions, the starting point for translating an informal specification is the decision tree:
Partial Translation TransformationsThe following transformations of decision tree nodes with text carry out the translation of informal specifications into a decision tree without text nodes step by step. The set of rules below is a first attempt, and additional rules are expected to be found from translating informal specifications. Different TopicsA decision tree from an informal specification addressing different topics is the and of the decision trees of those topics. Given a node of the form,
transform to
Sequential BranchingGiven a node of the form,
transform to
And TranslationIf a text presents a set of requirements R1,..,RN that must all be satisfied, transform
Or TranslationIf a text presents a set of requirements R1,..,RN that is satisfied if any are satisfied, transform
into
Atomic Formula TranslationIf text can be translated into an atomic formula A, transform
into
A similar transformation holds for tests. Empty Text Node DeletionTransform
into
Logical Equivalence SimplificationA tree can be transformed if its logical value is never changed. An example is double and elimination. Transform
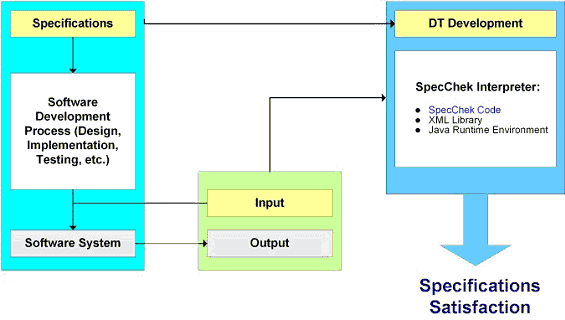
SpecChekTMSpecChek is a computer program that interprets decision trees of the type described above, developed as part of this handbook project. When a specification is written as a decision tree, SpecChek can be used to determine whether a program meets its specifications. An executable version of SpecChek and complete user documentation is available on the SpecChek homepage.(8) How SpecChekTM Is UsedThe following diagram shows how SpecChek is used in checking software against its specifications.
Legend: DT = "decision tree" Preparations for Checking SoftwareBefore running SpecChek:
Checking SoftwareTo setup a SpecChek run:
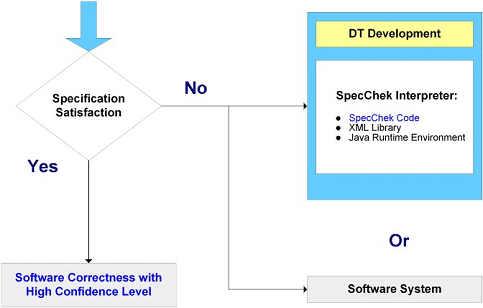
Legend: DT = "decision tree" Interpreting SpecChek ResultsCase 1: Interpreting Specification SatisfactionIf SpecChek reports that the specifications are satisfied, there are two possibilities:
Usually, a SpecChek report of satisfaction reports the real thing. The independence of the tested program and SpecChek decrease the probability of a false positive. As specifications become more exacting, a false positive becomes less likely. Case 2: Interpreting Specification FailureIf SpecChek reports that the specifications fail, there may be an error in:
Finding the Cause of FailureTo find the cause of specification failure with such a diverse set of possible errors, use SpecChek's reasoning report to see why SpecChek thinks the specifications fail. The error can be located by checking the logic in this report. As illustrated in the example below, the error is usually in the program being tested. When developing or using a new decision tree, the error is sometimes in the decision tree or in the specifications put into the tree. Although it has not been reported yet, it is possible that the error is in SpecChek or in the infrastructure for SpecChek. However, while most programs hide their errors inside the computer, SpecChek provides all the information users need to either verify SpecChek's correctness or pinpoint its error. The Importance of the Reasoning ReportThe reasoning report of why a program passed or failed the specifications is a key to checking the performance of deployed software. Because of the low probability of false positives, reports of specification satisfaction need not be checked thoroughly. For reports of specification failure, a report of the reasoning behind failure provides a practical way for engineers or other domain experts to determine whether and why the target program actually failed. Because the reasoning report allows the identification of false negatives due to errors in SpecChek, having a readable reasoning report makes it possible to use SpecChek even though the application may contain bugs. This is important, because it is not possible with today's technology to guarantee that any piece of software as large as SpecChek is free of bugs, or that a particular run is free of errors caused by the underlying computer system. (Of course, if there are too many false positives, SpecChek is not useful. However, experience to date has not revealed any false positives from the current version.) More about the Reasoning ReportThis section discusses how to interpret SpecChek's reasoning report in greater detail. Interpreting a Report of SatisfactionIf SpecChek reports that the decision tree of specifications was satisfied, there are two possibilities:
Satisfying engineering decision trees usually involves satisfying equations up to a small error tolerance and satisfying numerical inequalities that specify acceptable ranges for output variables. To estimate accurately the probability that such specifications were satisfied while both SpecChek and the target program contained errors generally requires problem-specific reasoning. However, the general comments below show that this probability is usually very small for engineering applications. Most engineering specifications contain formulas that are applied to inputs. The chance that two erroneous calculating agents (SpecChek and the target program) would randomly produce equal results (within tolerance) out of all the possible real number answers is very small, provided that the computations resemble Bernoulli trials (the SpecChek and target program calculate their results independently). Complete independence of the SpecChek and target program calculations generally are not achieved. For example, both may be run on the same computer, so errors in the arithmetic chip could produce outcancelling errors in each computation. However, the following implementation features make SpecChek's calculations significantly independent of those in the target program:
In addition, SpecChek contains various features that were designed to minimize errors to decrease the probability of a false positive. These are discussed in more detail below. Because the probability of a false positive is small, a report of specification satisfaction reasonably can be interpreted as actual specification satisfaction. Other Sources of False PositivesThe above discussion focused on false positives that are due to outcancelling errors in the target program in SpecChek. However, there is also the possibility that a specification failure was not found because the XML decision tree did not correctly encode the underlying engineering specification. There is no guaranteed way to eliminate this source of error. However, it can be minimized by carefully writing and reviewing the specifications. Because the XML specifications are relatively brief and readable by engineers, this checking and review is feasible. If carried out by multiple independent reviewers, it is likely to catch most errors. The reliability of a decision tree also is increased by basing the decision tree on established engineering specifications. These specifications generally have been subjected to intensive reviews, so that errors in the decision tree probably occur from translating the natural-language specifications into XML rather than from errors in the specifications themselves. For a discussion of estimating errors in knowledge bases, see Verification, Validation, and Evaluation of Expert Systems, an FHWA Handbook.(5) Interpreting a Report of FailureIf SpecChek reports that the decision tree of specifications was not satisfied, there are two possibilities:
As discussed below, care has been taken to reduce the probability of an error in SpecChek. However, it is assumed that SpecChek, like almost all software, contains some bugs. When specifications are not satisfied, it must be determined whether the error is in SpecChek or in the program being tested. The way to make this determination is to manually check the reasoning in the SpecChek report. This report describes why SpecChek thinks the decision tree is not satisfied; it is usually one page or less-small enough to be reviewed manually. If the reasoning in the SpecChek report is sound, the error is in the target program. If the reasoning in the SpecChek report is unsound, the error is in SpecChek. However, sometimes the specifications were not satisfied because the target program was correct and there was an error in the specification decision tree. Examining the chain of reasoning in the SpecChek report should help locate errors in the decision tree. SpecChek's Own ReliabilitySpecChek, like almost all software, likely contains bugs. This section discusses:
How SpecChek Bugs Affect UsersIt does not matter for a particular specification satisfaction report whether SpecChek contains bugs in general; what matters is whether one of those bugs has made that particular report incorrect. This can be determined by manually checking the SpecChek report for the reasoning that led to its conclusion about specification satisfaction. If the reasoning in the SpecChek report is sound based on the decision tree of specifications, the conclusion is valid, even if the SpecChek software contained bugs, and even if some of these bugs were activated in the SpecChek computation. Because SpecChek reports its reasoning, the significance of SpecChek bugs is reduced, and any such bugs are as easy to find as possible. How the Design of SpecChek Reduces the Likelihood of Bugs
Using SpecChek in the Software Life CycleDuring the software life cycle, SpecChek can be used to promote software reliability:
Advantages of SpecChek for Wrapping
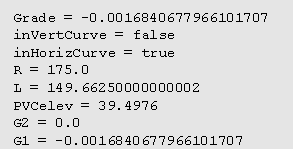
An ExampleThe following decision tree encodes part of the specifications for the design consistency module of IHSDM. Note that the decision tree consists of logic built over equations and inequalities that relate variables such as V85, familiar to design engineers working in this area.
SpecChek was run on files of input and output data like the following file of input data. (Supplemental software was written to extract this data from a Computer-Aided Design (CAD) file.)
When SpecChek was run on inputs and outputs to which some noise had been added, it generated the following report of failure:
|


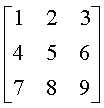








![<and> <text> [put the entire informal specification here] </text> <and>](images/matrixeq_11.gif)
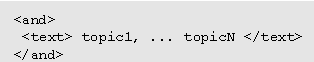






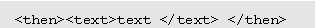
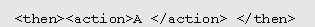

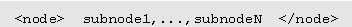
![<and><and> [whatever] </and>into <and> [whatever] </and>](images/matrixeq_18.gif)