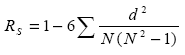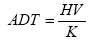U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-08-051
Date: June 2008 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Surrogate Safety Assessment Model and Validation: Final ReportPDF Version (3.39 MB)
PDF files can be viewed with the Acrobat® Reader® Chapter 3. Theoretical ValidationThe validation effort for SSAM consists of a theoretical validation, field validation, and sensitivity analysis. This chapter presents the theoretical validation effort. PurposeThe main purpose of theoretical validation of SSAM is to determine if the surrogate measures computed with the SSAM approach can discriminate between intersection designs in a simulation model. The secondary purpose of the theoretical validation effort is to identify any correlation between the surrogate measures produced by the SSAM approach and existing crash prediction models available from the literature. MethodologyThe hypothesis for the utility of surrogate measures of safety is that they will discriminate between two design alternatives implemented in a simulation. This involves the following steps:
In addition, this effort also includes analysis of the following:
Implement Alternative Intersection DesignsAs discussed in chapter 1, the resulting frequency and severity distributions of the conflict events that occur in the simulation are hypothesized to represent the surrogate measures of the safety of a particular intersection design. To evaluate the viability of using these measures for assessing safety, alternative intersection designs have been implemented in microscopic simulation systems and the corresponding output surrogate measures of safety for each conflict event or aggregation of the conflict events among alternative designs have been compared. The intersection designs studied include many of the intersection types that are used in the real world. For each set (or pair) of alternative designs, traffic conditions (e.g. volumes for each approach, vehicle class, speed limit, driver's aggressive distributions, gap acceptance threshold, etc.) have been configured identically in order to make the alternatives comparable. Where alternative traffic flow scenarios were investigated, with a range of volumes and/or turning probabilities, the same conditions were applied to both intersection designs in the design-pair to maintain a reasonable basis for comparison. To ensure statistically representative measures for comparison, each situation was replicated 10 times for each design alternative. Measures of Discrimination Between DesignsAfter running the simulation for each design, the corresponding surrogate measures were collected with SSAM, and statistical distributions of various aggregations were compared by the following:
The analysis of design alternatives has been conducted in a comparative manner because the essential information is more likely found in the differences between the results for two scenarios rather than from the absolute results for a particular scenario. Data from One Simulation RunAfter each simulation run, the vehicle trajectory data were processed by SSAM to compute the surrogate measures. For each conflict event identified by SSAM, the following has been recorded:
An example of the data collected is shown in table 1. More data are collected on each event than is shown in the table below. Refer to the SSAM user manual for detail of all measures collected by SSAM. SSAM classifies each conflict event as one of three conflict types: crossing, lane-change, or rear-end. Conflict type classification is based on the ConflictAngle, as defined in chapter 2. During the theoretical validation study, the conflict type was classified as a rear-end conflict if ||ConflictAngle|| < 2 °, a crossing conflict if ||ConflictAngle|| > 45 °, or a lane-changing conflict if 2 ° ≤ ||ConflictAngle|| ≤ 45 °. However, it is important to note that the classifications logic of SSAM changed subsequent to the theoretical validation in this chapter to achieve more accurate classification. (The revised logic appears in its entirety in the definition of ConflictType in chapter 2.) Revising the classification logic allowed recognition that many of the lane-change conflicts in a particular AIMSUN round-about model were actually events between pairs of vehicles on the same link and in the same lane. These events were clearly rear-end events, but due to the curvature of the roadway, the difference in vehicle headings (i.e., the conflict angle) exceeded the 2 ° threshold for a rear-end event. The revised logic improved classification, though there are still "gray area" cases (e.g., a vehicle entering into a roundabout collides with a vehicle within the roundabout) where classification of an event as crossing, lane-changing, or rear-end is arguably a subjective judgment. Indeed, it could be argued that some conflicts are simultaneously of two or three types (e.g., lane-change and rear-end).
1 I—Crossing conflict event. II—Lane-changing conflict event. III— Rear-end conflict event. Table 1 is an example of the data available for each conflict event. Aggregated values or summary measures have also been collected, such as the total number of conflict events with TTC values in different severity ranges (e.g. 0 < TTC ≤ 0.5, 0 < TTC ≤ 1.0). This down-selection of the data is done by using the Filter function of SSAM. An example aggregation by conflict type is shown in table 2.
Note: The bar over the variable indicates the average value of that surrogate safety measure over all the conflict events of each conflict type. Statistical Results from Multiple Replications Each intersection design is simulated with multiple replications, each using different random number seeds, and statistical distributions of the results were collected and analyzed. For the intersection design alternatives, a sample size of 10 replications was used throughout this study. Comparison of Alternative Designs For each set (pair) of alternative designs, the output measures have been compared statistically to identify the significance of the difference between the designs. An example of this comparison is shown in table 3. The student's t-test was used to compare each type of surrogate safety measures and the frequency of conflicts for alternative designs. The t-test calculates the probability of the difference of the two means. In this test, the null hypothesis (H0) indicates that the difference between the means of two samples is 0. Based on the difference level of the two sample variances, t-ratios and degree of freedom are calculated in different ways. Whether or not the sample variances are significantly different is verified by using the F-test before the t-test is performed. When the average number of events in a conflict type category and/or total conflicts is less than 0.5 (meaning that out of the 10 replications, an event occurs approximately every other simulation run), the data are marked as N/A, and no test outcome is recorded.
Table 3 and table 4 are examples of the statistical analyses that were performed in the theoretical validation study. Comparison to Predicted Crash FrequencyIn addition to the comparison analysis for each set (pair) of the alternative designs, the theoretical validation study also compared the relative values of surrogate measures of safety to predictions of safety from regression-based models of crash prediction developed and calibrated by others. Regression models were used to calculate the expected crash frequency for each simulated scenario. Lognormal regression models have been applied in this study. Specific models are used for each of the following for classes of intersections:
Many of the models presented in this chapter use the term accident instead of the term crash. Crash is the preferred term used in this document; however, these terms may be considered interchangeable. The term accident is retained at times due to the historical use of variables or acronyms, such as AMF, which stands for accident modification factor. Accident prediction models for urban, four-leg, signalized intersection are established by Harwood and Council:(13)
Figure 17. Equation. Accident Prediction Model for an Urban, Four-Leg, Signalized Intersection. Where:
Accident prediction for urban, four-leg, stop-controlled intersection are also given by Harwood and Council:(13)
Figure 18. Equation. Accident Prediction Model for an Urban, Four-Leg, Stop-Controlled Intersection. Where: A is the predicted number of total intersection-related accidents per year .
0.76 for one major-road approach. 0.58 for both major-road approaches.
0.95 for a right-turn lane on one major-road approach. 0.90 for right-turn lanes on both major-road approaches.
1.05 if sight distance is limited in one quadrant of the intersection. 1.10 if sight distance is limited in two quadrants of the intersection. 1.15 if sight distance is limited in three quadrants of the intersection. 1.20 if sight distance is limited in four quadrants of the intersection
SKEW is the intersection skew angle (degrees), expressed as the absolute value of the difference between 90 ° and the actual intersection angle.
Accident prediction models for urban, three-leg, signalized intersection (T-intersection) are given by Bared and Kaiser:(14)
Figure 19. Equation. Accident Prediction Model for a Three-Leg, Signalized Intersection. Where:
An accident model for urban, three-leg, stop-controlled intersection (T-intersection) is provided by Harwood and Council:(13)
Figure 20. Equation. Accident Prediction Model for an Urban, Three-Leg, Stop-Controlled Intersection. Where:
An accident prediction at a diamond interchange is given by Wolshon:(15)
Figure 21. Equation. Accident Prediction Model for a Diamond Interchange. Where:
Roundabout Crash prediction models have been developed for four-leg, signalized intersections in the United States, as discussed previously. However, no crash prediction models exist for U.S. roundabouts and driver behavior. Given the relatively recent introduction of roundabouts to the United States and driver unfamiliarity with them, crash prediction models from other countries have been used. Crash models relating crash frequency to roundabout characteristics are available from the United Kingdom. The British crash prediction equations for each type of crash are listed in figure 22 through figure 26. Note that these equations are only valid for roundabouts with four legs. However, the use of these models for relative comparisons may still be reasonable.(16) 1. Entry-Circulating:
Figure 22. Equation. Entry-Circulating Roundabout Accident Prediction Model. Where:
2. Approaching:
Figure 23. Equation. Accident Prediction Model for Roundabout Approaches. Where:
Figure 24. Equation. Single-Vehicle Accident Model for Roundabouts. Where: A are personal injury crashes (including fatalities) per year at roundabout approach or leg.
4. Other (vehicle):
Figure 25. Equation. Other Vehicle Accident Prediction Model for Roundabouts. Where:
5. Pedestrian:
Figure 26. Equation. Pedestrian Accident Prediction Model for Roundabouts. Where:
Since the current method only defines conflict events for pairs of vehicles, crash types 3, 4, and 5 (single, other, and pedestrian, respectively) have been ignored in using the prediction models for roundabouts. Comparison of Intersection Rankings by Conflict and Crash Frequencies Another important indicator that would validate SSAM would be a correlation of surrogate measures with predicted crash frequencies. Such a comparison has been performed for each comparison scenario in the theoretical validation study. To do this, first the simulation for each intersection design was run with different traffic volumes (low, medium, high annual average daily traffic (AADT)) and the corresponding conflicts (total conflicts and total number of conflicts of each event type) were analyzed. The results were then ranked from highest to lowest. Summary measures with the same values were assigned equal rank. For each design scenario, the predicted number of crashes using an existing crash prediction model was also calculated . This prediction is repeated for each level of traffic volume (i.e., AADT). A rank of the number of crashes was then established and compared to the ranking of number of conflicts of each type. Table 5 gives an example of the data needed for the correlation calculation. Table 6 shows an example of the paired rank data. The Spearman rank correlation coefficient was then computed to determine the level of agreement between each pair of rankings. The Spearman rank correlation coefficient is defined by
Figure 27. Equation. Spearman Rank Correlation Coefficient. Where: d is difference between ranks. N is number of paired ranks. Then the resulting correlation coefficient is compared with the critical coefficient value with the appropriate sample size and the significance level. If the absolute value of the coefficient is greater than the critical value, then it can be concluded that there is a rank order relationship between these samples. If the Rs value is -1, then there is a perfect negative correlation between the two sets of data. If the Rs value is 1, then there is a perfect positive correlation between the two sets of data. Table 8 provides a numeric example of this. In this example, we would find that the conflict data have a positive, but weak, correlation with the predicted crash frequency.
Note: M = average value of the measure.
Issues with Validation MetricsReconciliation of ADT with Hourly Volumes In crash prediction models, traffic volumes are in the unit of ADT while traffic volumes used in all of the simulation systems are in the unit of vehicles per hour. To ensure the consistency of the comparison, converting rules need to be applied to reconcile these two terms. By using K factors, we have converted ADT to vehicles per hour and vice versa as shown in figure 28:(17)
Figure 28. Equation. Using K-Factors to Scale Hourly Volume to Daily Volume. Where: ADT is the average daily traffic volume. HV is the hourly volume. K is the conversion factor. The K value should vary with different area types. For the general purpose of this study, values from the Highway Capacity Manual (2000) were used as shown in table 7:(17)
Where:
Overlapping Vehicles in TRJ Output ("Crashes") In each of the simulation models, some situations result in "virtual" crashes. These are situations where the logic in the simulation model does not accurately and completely represent the physical possibility of a particular maneuver. This does not happen frequently relative to the total number of traffic maneuvers being performed in a simulation; however, because the data are being analyzed at an extremely "nanoscopic" scale, SSAM identifies these modeling inaccuracies as conflicts with TTC = 0 ("crashes"). In this report, all crashes have been removed before the statistical calculations are performed. In some cases during the analysis of the theoretical validation data, it was observed that including the virtual-crashes in the analysis results in a different statistical determination. As many crashes as possible have been removed by appropriate modeling of the design case. For all the models tested, it is imperative that the analyst implement the design appropriately. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||


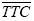
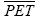
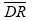
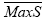
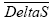
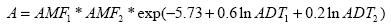
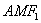 is the accident modification factor for the presence of left- turn lane:
is the accident modification factor for the presence of left- turn lane: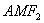 is the accident modification factor for the presence of right-turn lane:
is the accident modification factor for the presence of right-turn lane: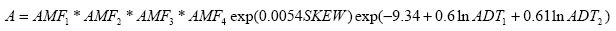
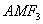 is the accident modification factor for the sight restrictions:
is the accident modification factor for the sight restrictions: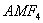 is 0.53, the accident modification factor for the conversion from minor road to all-way stop-control.
is 0.53, the accident modification factor for the conversion from minor road to all-way stop-control.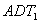 is the ADT volume (veh/day) on the major road.
is the ADT volume (veh/day) on the major road.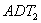 is the ADT volume (veh/day) on the minor road.
is the ADT volume (veh/day) on the minor road.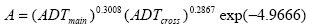
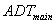 is the entering ADT on the main road.
is the entering ADT on the main road.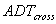 is the entering ADT on the crossroad.
is the entering ADT on the crossroad.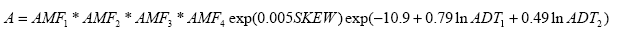
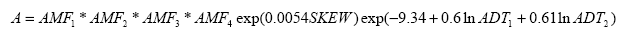
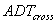 is the ADT volume (veh/day) on the cross-road.
is the ADT volume (veh/day) on the cross-road.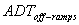 is the ADT volume (veh/day) on the off-ramps.
is the ADT volume (veh/day) on the off-ramps.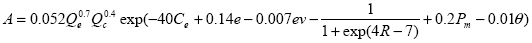
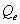 is entering flow (1,000s of vehicles/day).
is entering flow (1,000s of vehicles/day).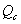 is circulating flow (1,000s of vehicles/day).
is circulating flow (1,000s of vehicles/day).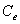 is entry curvature (
is entry curvature (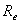 ).
).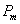 is proportion of motorcycles (percent, %).
is proportion of motorcycles (percent, %).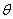 is the angle to next leg measured centerline to centerline (degrees, °).
is the angle to next leg measured centerline to centerline (degrees, °).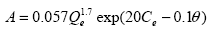
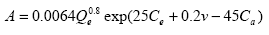
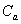 is approach curvature = 1/
is approach curvature = 1/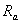 .
.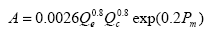
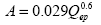
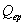 is the product (
is the product (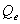 +
+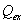 )
)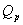 .
.