U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-96-143
Date: April 1997 |
Development of Human Factors Guidelines for Advanced Traveler Information Systems and Commercial Vehicle Operations: Definition and Prioritization of Research Studies
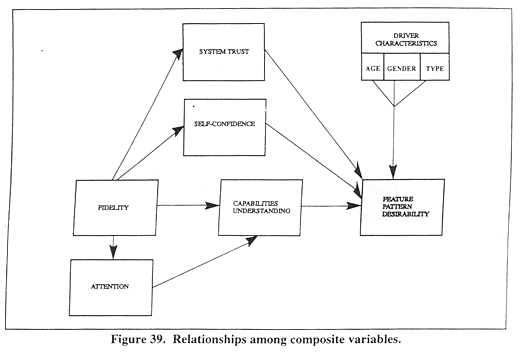
EXPERIMENT 1B RESULTSExamined in the analyses were 1 objective rating dependent variable and 93 subjective rating dependent variables. The objective dependent variable was the percent correct score for the CityGuide system capabilities items (appendix B, p. 213). This score indicated the drivers' understanding of the CityGuide system. The 93 subjective rating variables were factor analyzed as related groups of questionnaire items and used to create 8 composite variables. The analyses was conducted in three phases using the SPSS/PC+, version 5.0, software package. In the first phase, descriptive statistics and ANOVA's were calculated for items (appendix B, p. 236) that paralleled the TravTek User Test Questions reported in experiment 1. In the next phase, an ANOVA was used to examine the relationships between AGE, GENDER, and DRIVER TYPE, and the total percent correct score for the CityGuide system capabilities items. In the third phase of the analyses, three parts aimed at identifying the relationships among the variables shown in figure 39. Results from each phase of the analyses are described below. ANOVA tables are presented in appendix C (pp. 261–268).
Phase 1. CityGuide System User Test Questions – Descriptive StatisticsIn the first phase of the analyses, a subset of questionnaire items that paralleled the TravTek User Test Questions was analyzed with descriptive statistics and ANOVA for AGE (younger = 18–54 years, older = 55–85 years), GENDER (male, female) and DRIVER TYPE (private, commercial). DRIVER TYPE was a covariate in the analyses rather than a separate factor since all commercial drivers were younger and male. The CityGuide system questionnaire items are listed in table 28 and are shown in appendix B under the heading CityGuide User Test Questions (p. 236). The items are related to information presentation formats (i.e. map display, text instructions) and overall ease of use and learning. Relevant means for these items are shown in figure 40 through figure 49 as a function of AGE. Then a repeated–measures analysis was performed for each of these items. Table 28. CityGuide system user test questions.
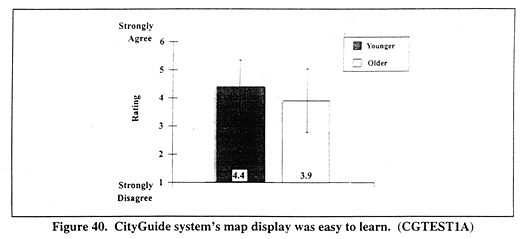
Figure 40 (CGTEST1A) shows mean ratings for the CityGuide system's map display ease of learning as a function of AGE. Error bars in this and subsequent figures indicate standard deviations. The ANOVA resulted in a significant main effect for AGE, F(1,122) = 9.09, p < 0.003. Younger drivers' ratings (mean = 4.4) indicate that they thought the map display was easier to learn than older drivers (mean = 3.9).
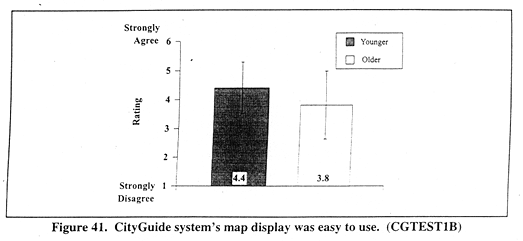
Figure 41 (CGTEST1B) shows mean ratings for the CityGuide system's map display ease of use as a function of AGE. A significant main effect occurred for AGE, F(1,120) = 10.9, p < 0.001. Younger drivers' ratings (mean = 4.4) indicated that they thought the map display was easier to use than older drivers (mean = 3.8).
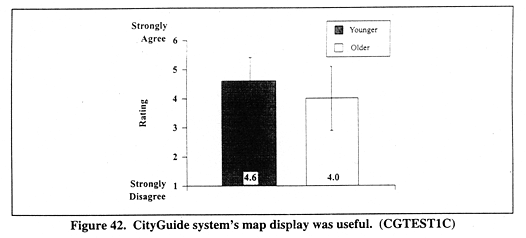
Figure 42 (CGTEST1C) shows mean ratings for the CityGuide system's map display usefulness as a function of AGE. A significant main effect occurred for AGE, F(1,121) = 11.4, p < 0.001. Younger drivers' ratings (mean = 4.6) indicate that they thought the map display was more useful than older drivers (mean = 4.0).
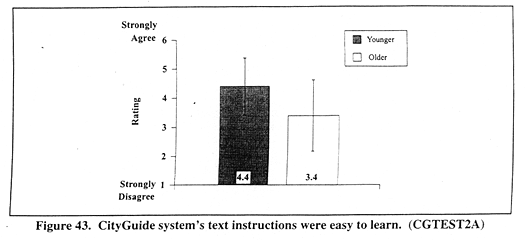
Figure 43 (CGTEST2A) shows mean ratings for the CityGuide system's text instructions ease of learning as a function of AGE. A significant main effect occurred for AGE, F(1,120) = 27.3, p < 0.001. Younger drivers' ratings (mean = 4.4) indicated that they thought the text instructions were easier to learn than older drivers (mean = 3.4).
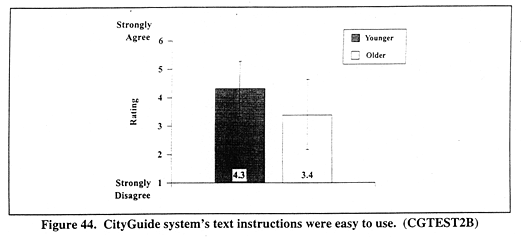
Figure 44 (CGTEST2B) shows mean ratings for the CityGuide system's text instructions ease of use. A significant main effect occurred for AGE, F(1,118) = 21.4, p < 0.001. Younger drivers' ratings (mean = 4.3) indicate that they thought the text instructions were easier to use than older drivers (mean = 3.4).
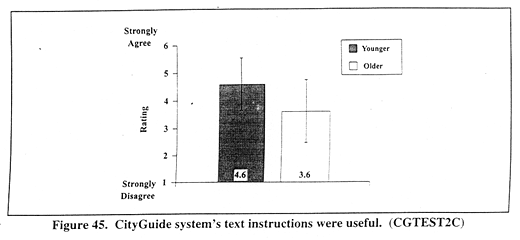
Figure 45 (CGTEST2C) shows mean ratings the CityGuide system's text instructions usefulness as a function of AGE. A significant main effect occurred for AGE, F(1,120) = 23.8, p < 0.001. Younger drivers' ratings (mean = 4.6) indicated that they thought the text instructions were more useful than older drivers (mean = 3.6).
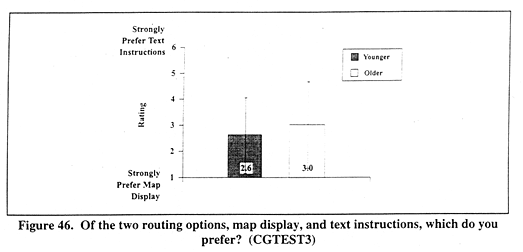
Figure 46 (CGTEST3) shows mean ratings for display preference. Younger drivers' mean rating was 2.6, while older drivers mean rating was 3.0.
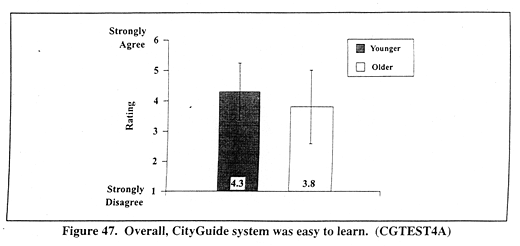
Figure 47 (CGTEST4A) shows mean ratings the CityGuide system's overall ease of learning. A significant main effect occurred for the covariate, DRIVER TYPE, F(1,118) = 4.53, p < 0.035. Commercial drivers, all younger and male, rated the ease of learning (mean = 3.7) the same as the older, private male drivers (mean = 3.7). Commercial drivers' mean rating was less than that of private male drivers in the same age group. Overall, there was a significant main effect for AGE, F(1,118) = 11.4, p < 0.001. Younger drivers' ratings (mean = 4.3) indicate that they thought the CityGuide system was easier to learn than older drivers (mean = 3.8).
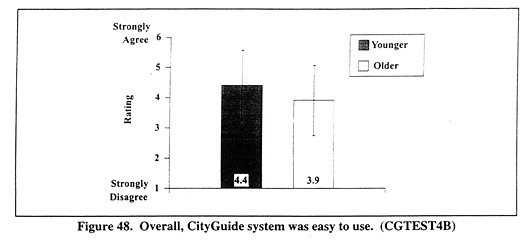
Figure 48 (CGTEST4B) shows mean ratings for the CityGuide system's overall ease of use. A significant main effect occurred for AGE F(1,116) = 11.2, p < 0.001. Younger drivers' ratings for ease of use (mean = 4.4) were higher than older drivers' ratings (mean = 3.9).
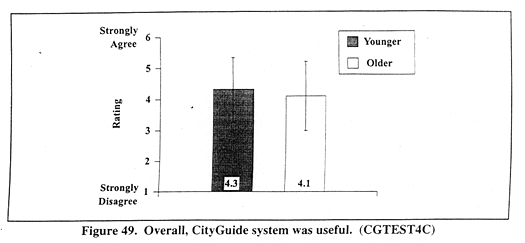
Figure 49 (CGTEST4C) shows mean ratings for the CityGuide system's overall usefulness. Younger drivers' mean ratings were 4.3 while older drivers' mean ratings were 4.1.
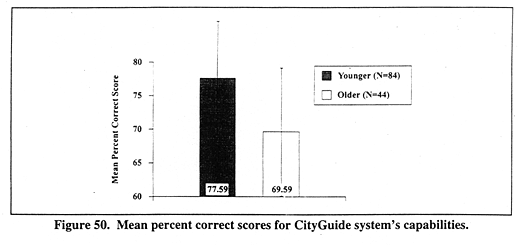
Phase 2. Age, Gender, Driver Type, and Mean Percent Correct Scores on the CityGuide System User TestThe second phase of the analyses examined AGE, GENDER, and DRIVER TYPE relationships for the overall percent correct score for the CityGuide system capabilities items. An ANOVA indicated that a significant main effect occurred for AGE, F(1,123) = 30.1, p < 0.001. Figure 50 shows that younger drivers had a higher mean percent correct score (mean = 77.6 percent) than older drivers (mean = 69.6 percent).
Phase 3. Identifying Relationships Among VariablesAs with the results of experiment 1, the last phase of the analyses was conducted in three steps aimed at identifying relationships among the variables shown in figure 39. During the first step, the feature patterns were determined via a factor analysis of driver responses on the CityGuide System Features Desirability questionnaire. Mean values and other descriptive results for individual features were also developed. During the second step, composite variables were developed from the individual questionnaire items. The first–order relationships among these composite variables were then explored correlationally. The results of this second step supported the regression–analysis evaluation of the relationships among the individual desired feature patterns and other variables during the third phase. The third step resulted in an understanding of the connection between the feature patterns, demographic variables (AGE, GENDER, and DRIVER TYPE), and the derived composite variables (i.e. system trust, self–confidence, etc.). Results of the three steps of the analyses are described below.
Feature PatternsThe feature patterns were derived and verified from the results of the respective factor analyses of 34 unfamiliar and 34 familiar-city responses on the CityGuide System Feature Desirability questionnaire (appendix B, p. 216). Three items were dropped from the analyses as they were added to the survey after the first 20 subjects. The primary focus was on the unfamiliar-city features because of expectations that drivers would require the most comprehensive sets of features in unfamiliar cities (and unfamiliar portions of familiar cities). The derivation and verification processes are described in the following subsections. Deriving the Feature Patterns As a first step in the analyses to derive the feature patterns, the mean values for the CityGuide system feature desirability items were calculated. Features with mean desirability ratings greater than or equal to 1.5 made up the most desired features category. Table 29 lists these 27 features. Table 29. CityGuide system most desired features.
Features with mean desirability ratings less than or equal to 0.5 made up the least desired features category. Table 30 lists these six features. To summarize, the most desired features were position of interest spots, text information about these "interest spots", route distance and route guidance alternatives, and general and other travel/routing information. All of the most desired features were for unfamiliar–city applications. The majority of least desired features related to text information about shops, coordination of travel with airlines, and text information about parking. Table 30. CityGuide system least desired features.
No CityGuide system feature patterns had a desirability rating of less than 0.5. These results do not explain why certain feature patterns are more or less desirable. More specifically, they do not reveal how variables such as driver characteristics, attitudes, and understanding influence feature pattern desirability. This factor analysis method was used to first identify feature patterns and then identify variables that influence these feature patterns. This factor analysis approach reduced the numbers of individual analyses from the total number of feature patterns (34 for unfamiliar–city driving and 34 for familiar–city driving) to a more manageable number of feature patterns (four for unfamiliar–city driving). Reducing the number of analyses avoided a large experiment–wide error rate and provided a more parsimonious model for driver acceptance. Moreover, it was expected that these feature patterns would represent integrated functional groupings that drivers would expect in the actual final ATIS design. Table 31 summarizes the method for determining the feature patterns from the unfamiliar–city responses following an approach, as was the case in experiment 1, featuring a Scree–test cutoff (Harmon, 1976) that typically is more parsimonious than a unity eigenvalue cutoff (hence, the minimum eigenvalue was 1.7 in the present case). Additionally, the Varimax procedure was used to orthogonally rotate the resulting factors to facilitate their interpretation (cf., Harmon, 1976). Table 31. Method for determination of feature patterns.
The results of the principal factor analysis were four feature patterns summarized in table 32. It can be seen that two of the feature patterns, Recreational Information and Accommodations Related Information (Feature Patterns I and III) were respectively defined by recreational and accommodation–related information feature patterns. In contrast, the other two feature patterns, Routing Assistance (Feature Pattern II) and Restaurants and Other Coordination (Feature Pattern IV) were more assistance–coordination oriented. Table 32. Desired feature patterns.
Verifying the Feature Patterns The derived feature patterns were "verified" for the familiar–city responses by comparison of unfamiliar– and familiar–city feature pattern scores. The results of the familiar–city responses were first factor analyzed following the unfamiliar–city approach described in table 31. The familiar–city factor analysis revealed four factors that appeared to be largely consistent with those summarized in table 32. To more conservatively evaluate this consistency, the separate feature pattern scores of unfamiliar– and familiar–city results were cross–correlated. Table 33 summarizes the results of the cross–correlation of the respective sets of four unfamiliar– and familiar–city factor scores. The dominant weights in each row and column indicate that the unfamiliar–city feature pattern scores generally had substantial overlap with those for the familiar–city. More specifically, the table shows that the familiar–city feature patterns, Recreational Information, Routing Assistance, Accommodation Related Information and Restaurant and Other Coordination, were most identified by respective unfamiliar–city feature patterns Routing Assistance, Recreational Information, Accommodation Related Information, and Restaurant and Other Coordination (respective correlations of 0.59, 0.53, 0.52, and 0.63). For example, some elements of the unfamiliar–city Feature Pattern III, Accommodation Related Information, are associated with the familiar–city Feature Pattern I, Recreational Information. Likewise, somewhat de–emphasized (–0.30) in familiar–city Feature Pattern III, Accommodation Related Information, are some elements of unfamiliar–city Feature Pattern IV, Restaurant and Other Coordination, e.g., Yellow Pages. The results show that the unfamiliar–city feature patterns are generally verified by the familiar–city results, with differences representing relatively minor fine tunings. Table 33. Cross–correlations between unfamiliar–city and familiar–city factor scores of the feature patterns.
Composite Variable EvaluationsComposite variables were evaluated in two stages. First, using factor analytic methods, composite variables were derived from the four sets of relevant questionnaire responses:
Due to less clearly defined system components than the TravTek system, the overall percent correct score for the CityGuide system capabilities items was used rather than factor scores on correct percent scores for system components. Tolerance pattern items were not asked during this study because they were not addressed by the CityGuide system functions. Second, the first–order relationships among the derived feature pattern variables were then explored in terms of the model shown in figure 39. The factor analyses and correlations are described in the following subsections. Derivation of the Composite Variables Table 34 summarizes the common method used for deriving the composite variable factors. This method is analogous to that employed earlier to derive the feature patterns. Table 34. Method for determination of composite variables.
Results of applying this method to each of the four sets of composite variables are summarized in the following:
These PFA results were generally consistent with the earlier analyses conducted in experiment 1. Specifically, the correlations of items with their respective subjective variables (FIDELITYC, SYSTRUSTC) were nearly identical with those seen earlier in experiment 1. This consistency supported the evaluation of the first-order correlations between the various composite variables and multivariate evaluations of their relationships with the desired feature patterns. Composite Variable First–Order Relationships Table 35 summarizes the first–order correlations among the factor scores for the feature patterns computed for the four composite variables and the capabilities understanding variable, percent correct score (UNDRSTDC). Examining the correlations between the variables, it is apparent that they are generally consistent with those observed earlier during the evaluations of the TravTek system. For example, it may be seen that the two largest positive correlations are again between the respective FIDELITYC and ATTENTC (r = .65 vs. 0.54 seen earlier in experiment 1) and the FIDELITYC and SYSTRUSTC variables (r = 0.40 matching what was seen earlier). These composite variables will be seen to play important roles in predicting the CityGuide system feature patterns seen in the next section. Table 35. Composite variable correlations.
Relationships of Feature Patterns with Specified VariablesThe third step was directed at the overall relationships among each of the four feature patterns and the selected variables shown in figure 39. Hence, four multiple correlation analyses were conducted that evaluated the joint relationships of each of the feature patterns scores with the following:
First, an initial multiple correlation was performed to identify relationships among the feature pattern's scores and all of the previously listed variables. Each of these initial analyses will be shown in a table. Then, the initial multiple correlation models were evaluated using a step–down procedure. Each of these final correlation models will also be shown in a table. A description of the table headings is given below:
"B" is the raw weight of the variable in the regression equation: yi = constant(additive) + j Bjxji where Yi is the driver's score on a variable, Bj is the jth variable's "B" weight, and Xji is the ith driver's score on variable j. Results for the four feature patterns are presented below in the order of their earlier numbering (i.e., Factors I to IV). Recreational Information Feature Pattern (Factor I) The initial analysis revealed a highly significant (p < 0.003) multiple correlation between the seven independent variables and the Recreational Information feature pattern: R = 0.409. Table 36 summarizes the model resulting from this analysis in terms of the raw weight of a term in the model (B); its standard error (SE B); the standard score model weight (BETA), the t-test value for the term (T); and its associated significance (p) value (SIG T). It is apparent that only one variable is initially significant (p < 0.003): type (commercial drivers were -0.84 below private). Others are clearly unrelated to the model (e.g., AGE with p > 0.9). These results suggested examination of simplified multiple correlation models that might better reveal the relationships with the Recreational Information feature pattern. Table 36. Recreational information feature pattern initial analysis summary.
Simplified multiple correlation models were evaluated using a step–down procedure that progressively eliminated variables with the largest significance levels greater than p = 0.10 (Norysis, 1992). This procedure revealed a very highly significant (p < 0.0003) multiple correlation among three remaining independent variables and the Recreational Information feature pattern: R = 0.378. Table 37 summarizes the model resulting for this analysis and shows that the significant (p < 0.04) model variables included: SELFCONC, TYPE, and UNDRSTDC. Table 37. Recreational information feature pattern final analysis summary.
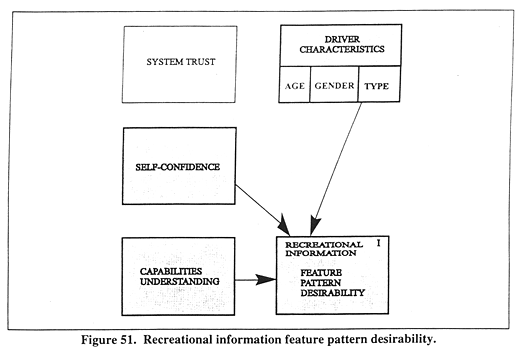
Figure 51 illustrates the relationships among these variables in the context of the other potential influences. These results indicate that as drivers with higher SELFCONC and UNDRSTDC find this feature pattern more desirable (B = 0.18 and 0.02, respectively). However, not surprisingly, commercial drivers (TYPE = 2) find the Recreational Information feature pattern substantially less desirable (B = -.72) than do private drivers (TYPE = 1). These results point out the considerable disinterest of commercial drivers in the Recreational Information feature pattern.
Routing Assistance Feature Pattern (Factor II) Initial analysis revealed a highly significant (p < 0.005) multiple correlation among the seven independent variables and the Routing Assistance feature pattern: R = 0.395. Table 38 summarizes the model resulting from this analysis. It is apparent that only one variable is initially significant (p < 0.05): UNDRSTDC. Others are clearly unrelated to the model (e.g., AGE X GEN with p > 0.8). These results suggested examination of simplified multiple correlation models that might better reveal the relationships with the Routing Assistance feature pattern. Table 38. Routing assistance feature pattern initial analysis summary.
Simplified multiple correlation models were evaluated using a step–down procedure that progressively eliminated variables with the largest significance levels greater than p = 0.10 (Norysis, 1992). This procedure revealed a very highly significant (p < 0.0003) multiple correlation among three remaining independent variables and the Routing Assistance feature pattern: R = 0.381. Table 39 summarizes the model resulting for this analysis and shows that the clearly two–tailed significant (p < 0.05) model variables included: TYPE, UNDRSTDC and AGE. Table 39. Routing assistance feature pattern final analysis summary.
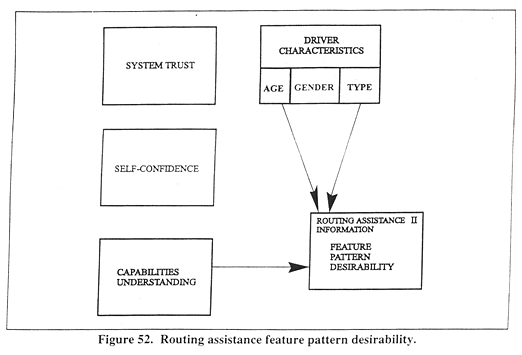
Figure 52 illustrates the relationships among these variables in the context of the other potential influences. Additionally, based upon an a prior prediction of increased desirability for commercial drivers, TYPE was also significant (p < 0.05 with a B = 0.42). The results also indicate that drivers with greater UNDRSTDC find this feature pattern more desirable but again older drivers find it less desirable than younger (respective B = 0.02 and –0.41). The Routing Assistance feature pattern desirability can be enhanced somewhat with education to increase UNDRSTDC, but it appears that much would be required to meaningfully offset the relatively large negative effects of AGE and positive effects of TYPE.
Accommodation-Related Information Feature Pattern (Factor III) Table 40. Accommodation related information feature pattern initial analysis summary.
Simplified multiple correlation models were evaluated using a step–down procedure that progressively eliminated variables with the largest significance levels greater than p = 0.10 (Norysis, 1992). This procedure revealed a very highly significant (p < 10–5) multiple correlation among three remaining independent variables and the Accommodation Related Information feature pattern: R = 0.456. Table 41 summarizes the model resulting for this analysis and shows that, in addition to the additive Constant, the clearly significant (p < 0.003) model variables included: SYSTRUSTC, TYPE, and AGE. Table 41. Accommodation related information feature pattern final analysis summary.
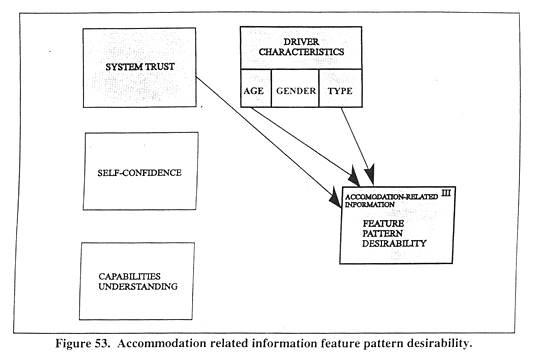
Figure 53 illustrates the relationships among these variables in the context of the other potential influences. The results indicate that drivers with higher SYSTRUSTC would find this pattern to have a higher desirability (B = 0.25). Contrasting with this, however, both commercial (TYPE) and older (AGE) drivers find this pattern less desirable than other drivers (respective B = –0.71 and –0.78). SYSTRUSTC, it is noteworthy to mention, likely plays a moderating influence above because Accommodation Related Information sources vary widely in the quality of their recommendations (same is also true for the Restaurant and Other Coordinations feature pattern). The Accommodation Related Information provided by advertising material, for example, is less valuable than more trustworthy information provided by an objective source (e.g., AAA). The desirability of such information consequently is strongly dependent on SYSTRUSTC and the factors that increase it, e.g., FIDELITYC.
Restaurant and Other Coordinations Feature Pattern (Factor IV) Initial analysis revealed a nonsignificant (p = 0.09) multiple correlation among the seven independent variables and the Restaurant and Other Coordinations feature pattern: R = 0.312. However, as indicated in table 42 that summarizes the individual variable results, SYSTRUSTC appears highly significant (p < 0.006) and TYPE appears marginally insignificant (p = 0.06). Still others appear clearly unrelated (e.g., UNDRSTDC with p > 0.8). These results suggested examination of simplified multiple correlation models that might better reveal the relationships with the Restaurant and Other Coordinations Pattern. Table 42. Restaurant and other coordinations feature pattern initial analysis summary.
Simplified multiple correlation models were evaluated using a step–down procedure that progressively eliminated variables with the largest significance levels greater than p = 0.10 (Norysis, 1992). This procedure revealed a highly significant (p < 0.005) multiple correlation between the only remaining variable, SYSTRUSTC, and the Restaurant and Other Coordinations feature pattern: R = 0.254. Table 43 summarizes the model resulting for this analysis and shows that increased SYSTRUSTC is associated with higher desirability for the Restaurant and Other Coordinations feature pattern (B = 0.25). Table 43. Restaurant and other coordinations feature pattern final analysis summary.
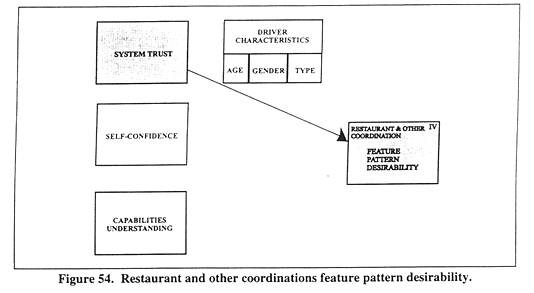
Figure 54 illustrates the relationships among these variables in the context of the other potential influences. Here, it is noteworthy, SYSTRUSTC likely plays a moderating influence for much the same reasons it did above for the Accommodation Related Information feature pattern. The desirability of information and coordination is strongly dependent on SYSTRUSTC when it can vary widely in quality. Hence, perhaps the only way of enhancing the desirability of the Restaurant and Other Coordinations feature pattern would be to increase the FIDELTYC, as it can be significantly related (r = 0.40) to SYSTRUSTC as shown earlier in table 35.
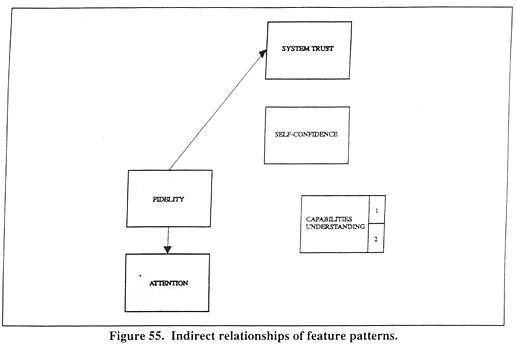
Fidelity and AttentionThe relationships among FIDELITYC, ATTENTC, UNDRSTDC, SYSTRUSTC, and SELFCONC were not directly considered in the section that describes the relationships of feature patterns with specified variables. This was, as may be recalled, because these variables were posited as only influencing the results through other variables. Therefore, only the direct relationships required analysis. Table 35 shows the correlations among the indirect variables. Of the five relationships predicted in figure 39, only the following two relationships were significant: 1) FIDELITYC and ATTENTC (r = 0.6548, p < 0.001) and 2) FIDELITYC and SYSTRUSTC (r = 0.3972, p < 0.001). Figure 55 illustrates these relationships.
FHWA-RD-96-143
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||