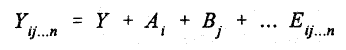U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-98-133
Date: October 1998 |
|||
Accident Models for Two-Lane Rural Roads: Segment and Intersections2. Literature ReviewSegment Models Miaou et al. (1993) used a model of Poisson type to estimate accidents along highway segments. Although the model was applied to truck accidents, it is applicable to other vehicles on a highway. Poisson regression provides one of the most suitable models because vehicle accidents are discrete rare events and accident counts are nonnegative integers. Accidents are usually positively skewed because of the high proportion of highway segments without accidents. Poisson regression models provide an easy linkage to probability, as opposed to other commonly used models such as multiple linear regression. The form of the model is:
For the i-th segment x1i = Average daily traffic per lane (in thousands of vehicles) x2i = Horizontal curvature (in degrees per hundred feet) x3i = x2i* horizontal curve length (in miles) x4i = Deviation of stabilized outside shoulder width per direction from 12 ft (in feet) x5i = Percent trucks in traffic stream. The estimated value of Poisson and negative binomial modeling techniques are believed to be robust and quite suitable for accident modeling. One weakness of the above model, though, is the minuscule frequency of truck accidents, since they constitute a very small proportion of total accidents, even though the highway sample of 14,731 lane-miles extending over a 5-year period is large. Another weakness may be ascribed to a highly significant variable, truck ADT (Average Daily Traffic). This variable was acquired from the Highway Performance and Monitoring System (HPMS), a separate data source that was integrated with the original data. Whether the values of truck ADT were sufficiently local to represent the truck traffic on a given segment adequately is not known. The report of Luyanda et al. utilized a variety of multivariate statistical techniques to investigate relationships between the major factors of rural highway conditions and accident occurrences. Cluster analysis, discriminant analysis, factor analysis, and linear regression were applied in stepwise fashion. Highway segments were divided into three groups: multi-lane segments, two-lane segments in flat and rolling terrain, and two-lane segments in hilly terrain. Comparisons were made between groups and within groups. Within the multi-lane segments, the significant variables identified by discriminant analysis were different from those identified by stepwise regression. For the other two groups, the R2 values were disappointingly low, 0.23 and 0.07, respectively. The report should be regarded as exploratory because of uncertainties in accident location and the small sample size. Although the results of the discriminant analysis seem to be reliable, they do not give a safety evaluation, but rather a classification by grouping. The assumption of linearity in the regression analysis is simplistic and should be refined. Moreover, highway segments and intersections were not differentiated to permit classification of accidents into segment accidents or intersection accidents. The reports of Zegeer et al. (1986), Mak (1987), and Zegeer et al. (1991) applied regression techniques to develop accident models for two-lane roads. The model for cross-section safety on two-lane highways proposed by Zegeer et al. (1986) is:
The accidents considered in this model are single vehicle accidents, head-on accidents, and same and opposite direction sideswipe accidents. A quadratic model for accidents on bridges was developed by Mak (1987):
Zegeer et al. (1991) developed a model for accidents on horizontal curves:
The last-mentioned study, Zegeer et al. (1991), reviewed data base characteristics, determined the important variables through a preliminary analysis, and then proceeded to model building. The preliminary analysis made use of several multiple linear regression models to identify significant or "important" variables. The authors reported that a linear accident rate model was much better than a log-linear model. For a nonlinear model they adopted and reparametrized an existing model. This model was a hybrid, with both linear and nonlinear components. Although the required statistical assumptions were not fully stated, use of the least-squares method was based on the assumption that the residuals would follow a normal or log-normal distribution. Because accident distributions are skewed to the right, normality is not a tenable assumption. Arguing that previous efforts were not sufficiently successful in attributing accidents to individual geometric elements and traffic characteristics, Kuo-Liang and Chin-Lung (1988) explored a technique that purported to remove the assumptions of normality and linearity. Their model was developed for two-lane rural roads. A technique called Automatic Interaction Detection (AID) was used to group roadway segments by selected or created categories of explanatory variables. These categories of variables maximize the difference between group sums of squares. Then a model was developed by the Multiple Analysis Classification (MAC) technique of the following form:
where Yij...n = the score of unit n that falls in category i of predictor A, category j of predictor B, etc Y = grand mean of the dependent variable Ai= the effect of membership in the i-th category of predictor A Bj = the effect of membership in the j-th category of predictor B ... Eij...n = error term for this unit. This method, though in part innovative, is still a variation on simple linear regression and accounts for only 33% of the total variance. The low predictive power may also be due to the lack of a horizontal alignment variable and small sample size. Durth (1989) used risk analysis to perform highway safety evaluation. This is quite different from conventional approaches to accident analysis and modeling. The method is well-known in the fields of nuclear power plants and chemical factories. Based on research in Germany from 1986, the claim is made that risk analysis can be successfully applied to traffic safety. A risk model relies on diverse information in modular and hierarchical form from different branches of sciences (medicine, mechanical engineering, civil engineering, psychology, etc.). It reconstructs known dependencies and identifies relationships that need to be verified. Although the method may be promising, the report of Durth does not clearly describe the substance of the research. Nor does it indicate how to develop the stated dependencies and how to verify them practically. Kulmala and Roine (1988) developed models for Finnish roads. They assumed a Poisson error distribution and intended their models to be used for prediction. Their typical model form was:
where A = total number of fatal and injury accidents on a segment S = exposure in vehicle-kilometers xi = explanatory variables such as surface width in meters, percentage of the segment length for which passing sight distance exceeds 300 meters, percentage of heavy vehicles, average curvature, and an interaction variable (pavement and speed limit). This multiplicative Poisson regression model is comparable to that of Miaou et al. (1993).
|