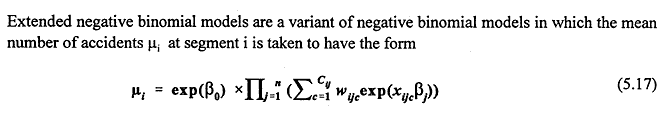U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-98-133
Date: October 1998 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Accident Models for Two-Lane Rural Roads: Segment and Intersections5. ModelingSegment Models In this section we develop models for segments. The models are of Poisson type, negative binomial type, and extended negative binomial type. We discuss the choice of variables and explain the steps that lead to the final models presented. The choice of variables to retain, and the form in which to use them, are to some extent arbitrary since not all possibilities can be examined and some are more or less equivalent. The decisions are guided by criteria of simplicity (use of variables that are easily understood), comprehensiveness (inclusion of as many types of variables as possible), and significance (coefficients that are significantly different from zero according to statistical tests in one or more models). Many models can be generated, and we present here only a selection of models that illustrate the main phenomena and/or show the significant interactions. In general, we will exhibit a formula for the mean number of accidents on a segment as a generalized linear function of highway variables. This formula will show the estimated coefficient of each variable in the model. In addition, we show the estimated standard error of the coefficient estimate and its P-value. The P-value is the probability that the estimated coefficient would have the value shown or any value farther from zero when the true coefficient is zero. A P-value of less than 5% is usually considered ample confirmation that the true coefficient is non-zero and that the estimated coefficient is significant. Later on, for the intersection models, we will liberalize this criterion considerably. The State Variable The STATE variable (value 0 for Minnesota, 1 for Washington) is used on all models that combine the two States. In effect it allows the constant or intercept term in each State to be different while constraining other coefficients to be the same. Including such a variable is equivalent to acknowledging that the accident experience of two different States is likely to be different on segments with the same traffic volumes and same highway characteristics. The STATE variable represents the demographics and habits of a different population of drivers in a different region and perhaps at a different era. Law enforcement practices, driver ages, and life styles may be quite different. Although the extra degree of freedom makes it easier to develop a combined model, it is of some interest when the coefficient of the State variable is insignificant (as it is in a few of the models below). The Exposure Variable For the segment modeling it is natural to include both segment length (seg_lng) and ADT as explanatory variables, and to expect that the number of accidents will be roughly proportional to the product of these factors times the time in days (365 days per year times 5 years in Minnesota or 3 years in Washington). Poisson models in Minnesota (Table 15) support this rough proportionality. If total number of accidents is modeled as a function of segment length and ADT, we obtain the following:
Table 15. Minnesota Segments, Poisson Models with Exposure Variables
1 mile = 1.61 km where LSEG is the log of the segment length and LADT is the log of AVGM (ADT in 1000's of vehicles per day). The Minnesota standard errors are consistent with the conclusion that the true coefficients of LSEG and LADT are 1. The second model shows the effect of using EXPO as an offset (i.e., as a multiplier) but retaining AVGM. The Minnesota data do not support the retention of AVGM. Similar tables for Washington State and the combined data sets (Tables 16 and 17) indicate that LSEG and LADT have coefficients near 1 but still significantly different from 1 since the estimated standard errors are small. Also, if EXPO is taken as an offset and AVGM is retained, the latter is found to be significant. Although other choices could be made, the decision was made to use EXPO as an offset and exclude segment length as a separate variable, with the expectation that additional effects apparently due to segment length can be represented by other highway variables. AVGM was retained in some runs, although, as will be seen, it was not significant in the final model.
Table 16. Washington Segments, Poisson Models with Exposure Variables
1 mile = 1.61 km
Table 17. Combined Segments, Poisson Models with Exposure Variables
1 mile = 1.61 km Lane Width and Shoulder Width Wider lanes and wider shoulders should lower accidents. If we add these two variables to the Poisson models (Table 18), some notable differences are found between Minnesota and Washington. The lane width variable is seen to be of unexpected sign and insignificant in the Washington data.
Table 18. Poisson Models of Segments with Lane and Surface Width
1 mile = 1.61 km, 1 ft = .3048 m In the last chapter we had already noted anomalies in the correlation between accidents and lane or shoulder width in Washington. Several factors contribute to this situation. One of them is the direct correlation between lane width and shoulder width that occurs in the Washington State data but not the Minnesota data. The correlation coefficients are given by:
The P-values are estimated probabilities that the correlation coefficient estimates would have the values shown or values farther from zero if there were zero correlation between the variables on the populations from which the data sets are samples. Minnesota lane widths and shoulder widths have a slight but not especially significant negative correlation, while Washington lane widths and shoulder widths have a significant positive correlation. This is also reflected when we consider univariate statistics for LW, SHW, and TOTWIDTH:
1 ft = .3048 m Another relevant fact is the shoulder composition in each State:
Washington shoulders tend to resemble the road surface more than Minnesota shoulders. This suggests the possibility that a more appropriate variable than either lane width or shoulder width might be the variable TOTWIDTH, total width of road and shoulders. When the shoulder is paved, drivers may not make as much of a distinction between it and the road, and the combined width may be the only important variable. When variables are dependent, it is sometimes useful to replace them with one significant combination. Against this it can be argued that lane width and shoulder width have different types of effects on accidents and that it is inappropriate to treat them as one additive variable. Indeed, in the final models we do not. Table 19 exhibits some models with only TOTWIDTH.
Table 19. Poisson Models of Segments with TOTWIDTH
1 mile = 1.61 km, 1 ft = .3048 m Comparison of these models with those using LW and SHW suggests that replacing LW and SHW by TOTWIDTH plus an adjusted intercept yields similar explanatory value. However, because of the importance of these two geometric variables and the fact that in principle their values are independent, we retain both variables to the extent possible. In a few runs below TOTWIDTH is used instead to facilitate comparisons between the two States. NOTE: Variables ACCRES = (Number of accidents minus predicted number from a Poisson model not using lane width LW) and LWRES = (LW minus predicted LW from a regression model using other highway variables) can be developed. Their correlation coefficients and associated P-values, not reproduced here, confirm that in Minnesota lane width has a significant independent negative effect on accident counts while in Washington lane width has an insignificant independent positive effect on accident counts. Horizontal and Vertical Curve Variables With the exception of the extended negative binomial models, in which individual horizontal and vertical curves were modeled, the horizontal variables used in this study have been the composites H, HM1, HM1.5, and HM2 and the vertical variables have been the composites VC, VM, VMC, and VMCC. All of these variables were found to be highly significant. The only oddity is shown in Table 20 below and concerns the joint effect of H (average horizontal degree of curve) and VC (sum of crest % grade changes per hundred feet weighted by relative crest curve lengths). In Table 20 the coefficients of the vertical and horizontal variables differ substantially between the two States and VC is insignificant in Washington with P-value .1854. If one replaces VC by VMC, an alternative measure of crest curves that sums the crest % grade changes per hundred feet over all crests and divides by segment length, the vertical variable becomes significant and its model coefficient stabilizes somewhat (but the horizontal variable H still shows dramatic change in its coefficient). See Table 21. There is of course strong correlation between the horizontal and vertical variables in both States.
It is possible that unimportant reweighting is occurring among variables that measure essentially
Table 20. Poisson Models of Segments with TOTWIDTH, H, and VC
1 mile = 1.61 km, 1 ft = .3048 m the same thing. In Washington 63.2% of the segments contain crest curves versus 83.5% of Minnesota's. However, the mean values of VC and VMC are higher in Washington and their standard deviations are much higher. It is perhaps not surprising that there would be differences between Washington and Minnesota in the coefficient estimates, but it is surprising that VC and VMC behave differently in Washington. VMC roughly measures the number of crests per mile (if one assumes that they all have about the same grade change per hundred feet), while VC measures the average grade change per hundred feet and assigns zero grade change to portions where no crest exists. VMC will be large if there are crests with large grade change per hundred feet, but VC will damp these down if they occur over short lengths (because they will be weighted by length). Because vertical and horizontal alignment are in principle independent and both are very important, we will retain both. We do this despite the fact that the correlation coefficients are considerably larger and more significant than those between lane width and shoulder width in Washington (which led us to introduce the combined variable TOTWIDTH). But in some runs we replace VC with
Table 21. Poisson Models of Segments with TOTWIDTH, H, and VMC
1 mile = 1.61 km, 1 ft = .3048 m VMC. The relationship between the vertical and horizontal measure will be reconsidered below when we use the extended negative binomial model, which takes into account individual curves on a segment. Grade, Roadside Hazard Rating, Driveway Density, and Other Variables Other variables systematically investigated in connection with model development include GR (average absolute straight-away grade), RHR (Roadside Hazard Rating), DD (driveway density), SPD (speed), T (commercial traffic %), and INTD (intersection density). Weather variables (NONDRYP and SNP) were also investigated in Minnesota. The weather variables can be dismissed at once. Both NONDRYP and SNP had negative regression coefficients in models and were not significant. A higher percentage of bad weather tends to accompany a decreased number of accidents, but the P-values are large. In a few runs SNP is marginally significant. Because the weather variable was not local but pertained to a large Weather District in the State of Minnesota and because of its relative insignificance, it was dropped from the modeling and was not collected in Washington State. See Shankar et al. for a study of weather variables in Washington State that indicates sufficiently local weather can be significant. Among the remaining variables, SPD is not significant in either State nor in the combined data set. This may in part reflect lack of variation in the speed data, as well as the quality of the speed data (speeds were not collected on some segments, but were later reconstructed from HSIS files). GR is very significant in both States. The other variables are significant in one State or the other (but not both) and significant in the modeling of the combined data sets. One curiosity is that T has a negative coefficient in Minnesota and is not significant, but has a significant positive coefficient in Washington. The P-values for these variables in Poisson runs on the combined data sets (with other variables LW, SHW, H, VC, and STATE; and with EXPO as an offset variable) are:
Next we attempt to include combinations of these variables in a combined Poisson model for both States. When this is done, GR and RHR do well, as do GR and DD, and GR and T. GR, RHR, and DD do well together (although STATE gets a P-value of .1417 in this case); and GR, RHR, and INTD do well together. Thus it is certainly appropriate to include GR and RHR in the model and at least one other variable. INTD measures intersection density. However, intersection accidents and intersection-related accidents are excluded from the accident variable in the segment models. For this reason, any effect of INTD will be indirect and INTD is not strictly comparable to DD (driveway density). This rules out a sum of DD and INTD as a measure. If GR, RHR, DD, and INTD are all included in the model, they have the respective P-values .0001, .0001, .0001, and .1863. We conclude that INTD does have an independent effect distinct from that of DD, but not sufficiently significant to include in the model. The situation is similar with the commercial traffic variable T. It appears to be significant for the combined data set, but not sufficiently - when other variables are present S for inclusion in the model. Table 22 shows resultant Poisson models for Minnesota and Washington. The anomalous behavior of lane width and VC in Washington exhibited in Table 15 has already been discussed. However, we should note the insignificance of Roadside Hazard Rating RHR in Minnesota. An interesting set of correlations exists with a bearing on the insignificance of RHR in Minnesota and the peculiar behavior of lane width LW in Washington.
RHR in Minnesota has a mean of 2.14 and a standard deviation of .97, while in Washington its mean is 3.67 and standard deviation 1.57. Roadside Hazard Rating is higher and more variable in Washington State. The insignificance of RHR in Minnesota in part relates to the absence of variation. The unexpected sign of the lane width coefficient in Washington likewise may be in part due to its correlation with the quite variable magnitudes of RHR in Washington. When the data from the two States are combined, this correlation becomes insignificant and the coefficients of LW and RHR both attain more plausible values. In Table 22 most coefficients for the combined model are intermediate between those of the two States. The most prominent anomalies are the negative sign of lane width in Washington, the
Table 22. Poisson Models for Segment Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
Table 23. Additional Poisson Models for Segment Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
insignificance of Roadside Hazard Rating RHR in Minnesota, and the insignificance of the crest variable VC in Washington. Table 23 shows a few variant Poisson models with characteristics of special interest. In Table 23 the insignificant variables from Table 22 are removed and other variables are introduced. In Minnesota AVGM and RHR have been removed, and SNP has been added (P-value = .1361). In Washington TOTWIDTH has replaced LW and SHW, and VMC has replaced VC. Also in Table 23 the combined data set is presented without AVGM but with the addition of T. The variable T is quite significant but STATE loses its significance (P-value = .3500). Poisson versus Negative Binomial For the models in Tables 22 and 23 the values of Dm/(n - p), X2/(n - p), and T1 are computed, along with several measures of goodness-of-fit. The goodness-of-fit measures indicate that the models have a good deal of explanatory power. However, the other statistics in all cases strongly support the conclusion that the data are overdispersed. In particular, the large values of T1 establish this decisively. The sources of the overdispersion are presumably segment characteristics not included in the model. Some of these characteristics might be items not collected (e.g., sight distances, superelevations, local weather) that are possible to collect, but others are items well outside the scope of this study (e.g., driver characteristics). Negative binomial models are a natural generalization of the Poisson that permit treatment of overdispersion. Such models can be developed with the software package LIMDEP or by trial and error with SAS and different choices of an overdispersion parameter. The negative binomial also has the advantage of lending itself nicely to application of empirical Bayesian techniques when past accident data are available at a site. An adjusted model can be developed with parameters partly derived from the past data and partly from the given negative binomial model. The new model makes use of the old but also allows the predictions of the old model to be tempered by actual experience on the roadway. See Hauer et al. (1988). The phenomena noted in the earlier Poisson models occur in the negative binomial setting: differences between the behavior of AVGM, lane width LW, VC and VMC, and RHR from one State to the other; and marginal significance of INTD and T. So the analysis is not repeated. In general the estimated coefficients of variables are similar to what they were under the Poisson models. However, we have an estimate for one additional parameter, the overdispersion parameter K. Table 24 shows four representative negative binomial models. The overdispersion parameters vary from 0.26 to 0.30. Variables that are omitted are not significant, and some that are retained are not as well S notably, intercept in three of the models, AVGM, and VC in the combined data set (and in Washington, not shown). AVGM is not at all significant in Minnesota, not very significant in Washington, and intermediate in the combined data set. Lane width has the wrong sign in Washington (not shown), and is less significant in the combined data set than it was in the Poisson.
Table 24. Negative Binomial Models for Segment Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
Table 25. Negative Binomial Models for Segment Injury Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
runs. The goodness-of-fit measures, including the ordinary R2, yield no dramatic conclusions. R2 K is systematically larger than the others. All the measures suggest that the Minnesota coefficients account for Minnesota accidents a bit better than the other models. Table 25 shows negative binomial models for serious accidents, based on the variable INJACC. Variables with little significance have been omitted and only those that are significant or marginally significant have been retained. The Minnesota model, with the fewest variables, once again has the highest goodness-of-fit. The coefficients are roughly comparable to those for the models for total number of accidents (TOTACC). Differences between the deviances Dm and R2 as one passes from Table 24 (TOTACC) to Table 25 (INJACC) are not of importance. Both measures tend to give smaller values when observed data are near zero, and larger values when the observations are away from zero: INJACC has small or zero values more often than TOTACC. The Extended Negative Binomial
instead of (5.1). With respect to the j-th highway variable, segment number i is decomposed into Cij subsegments of relative lengths {wijc : c = 1, ..., Cij} where the variables xij take the respective putatively constant values {xijc : c = 1,..., Cij}. In effect this model slices up the segments into subsegments where each variable is constant. The weights wijc are the relative lengths of the subsegments and add to 1. The value Cij can be taken to be independent of i (and j) if the maximum number of subsegments in the data set is specified: for segments with fewer subsegments the extra weights can be set equal to zero. For some variables, all weights except one are set to zero, and the model behaves like an ordinary negative binomial model with respect to them. An advantage of the extended negative binomial model is that it permits local variation along a roadway to be taken into account. Rather than summing local effects or averaging them, one in effect sums the accidents occurring on subsegments where conditions are constant. This givesthe model form a scale independence: one may decompose segments into subsegments or aggregate adjacent segments without changing model form.
Table 26. Extended Negative Binomial Models for Segment Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
Table 27. Final Extended Negative Binomial Model for Segment Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
Table 28. Extended Negative Binomial Models for Segment Injury Accidents Regression Coefficients (Estimated Standard Error and P-value in parentheses)
As with the negative binomial the goal is to estimate the coefficient vector In Table 26 AVGM and Roadside Hazard Rating RHR are strongly insignificant in Minnesota and so were removed. In Washington the crest variable V{j}, although having the correct sign, is strongly insignificant in the presence of the other variables and so was removed. In the combined data set AVGM (and the Intercept variable) are insignificant. When AVGM was removed and the commercial percentage variable T added, the estimated coefficient for T was positive but had a significance level of about 20%. When the speed variable SPD is added instead, it has a negative coefficient and a P-value of 50%. Table 27 represents our final model for segments. It contains a large number of variables, all of them significant, and it represents the combined characteristics of rural segments in two States with a reasonable amount of variation in all variables. Table 28 shows three extended negative binomial models for Injury Accidents. AVGM was insignificant in all three data sets. RHR and DD were insignificant in Minnesota. The straightaway grade variable GR{k} was not significant in Minnesota, and the crest vertical V{j} was not significant in Washington. Extended negative binomial runs with all variables present did not converge in the combined data set, but did when GR{k} was removed. A total of 36% of all reported segment accidents were Injury Accidents in Minnesota versus 46% in Washington, and this is reflected by the increase in the coefficient for State from Table 27 to Table 28.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||