Data Collection and Analysis
Background
In order to measure disparate impact, relevant demographic data for our projects and programs needs to be collected and analyzed to see if one protected class is disproportionately impacted compared to other groups. Please refer to Title VI – Types of Discrimination Factsheet for more information on disparate impact and its context within the Title VI program. This section will go over how to collect the data from the United States census, various ways to display and map that data, and how to do some basic entry level analysis of whether there is a disparate impact.
*** Disclaimer ***
This document is not intended as guidance, and it does not create new requirements or represent a statement of FHWA policy or interpretation of existing requirements. It is intended as an aid to recipients of federal financial assistance from the FHWA in the development of Title VI Plans, reviews, and other methods of administration. FHWA recipients should tailor their policies and procedures to suit their circumstances.
Please note that the U.S. Census will not provide Title VI demographic data for all situations. Some types of Title VI impacts—such as right of way/relocations and public involvement—will require Recipients to conduct surveys to collect demographic data from impacted persons. FHWA expects that recipients will make informed decisions on the appropriate sources of Title VI data. Recipients should contact their FHWA state division offices for any technical assistance needs.
Resources
U.S. Department of Justice (USDOJ) Title VI Website : The USDOJ coordinates Title VI compliance strategies and resources for all federal agencies. Its website contains useful information on Title VI.
USDOJ Title VI Legal Manual: This document is a comprehensive reference guide to Title VI caselaw and practice.
FHWA Civil Rights Office Census Add-On for Microsoft Excel: FHWA Office of Civil Rights Census Add-On for Microsoft Excel – Excel add-in that will generate percentages and summarize the area under review after downloading census information for the P2, P9, B03002, and C16001 tables. If you would like this Add-On, please email: CivilRights.FHWA@dot.gov
Sources of Data – U.S. Census
The US Decennial census is the best and most accurate source for getting demographic data. This section will give a brief overview of what the census is and how it gathers demographic data. When you go to the census website or to American Fact Finder you will likely encounter two different studies. The decennial census is conducted every 10 years. In the census, every person in the U.S. is surveyed and asked a series of ten questions. The American Community Survey is conducted annually using a random sample of American residents and contains a much larger set of questions.
Below is a picture of the 2020 census form with the demographic questions highlighted.

Question 8 asks, Is Person 1 of Hispanic, Latino, or Spanish origin? The options are No, not of Hispanic, Latino, or Spanish origin; Yes, Mexican, Mexican Am., Chicano; Yes, Puerto Rican; Yes, Cuban; Yes, another Hispanic, Latino, or Spanish origin – Print for example, Salvadorian, Dominican, Columbian, Guatemalan, Spaniard, Ecuadorian, etc. Question 9 asks What is Person 1's race? Mark x one or more boxes and print origins. The options are White, Black or African Am, American Indian or Alaska Native, Chinese, Filipino, Asian Indian, Other Asian, Vietnamese, Korean, Japanese, Native Hawaiian, Samoan, Chamarro, Other Pacific Islander, and Some other race.
The census includes two questions related to ethnicity and race. Question 8 asks the person whether they are of Hispanic, Latino, or Spanish origin and Question 9 asks for the person's race. These questions are answered independently of one another, and the census provides data on these two questions in multiple ways.
-
First, the data is available on the race (Black, White, American Indian, etc.) and the ethnicity (Hispanic or Latino) questions as separate topics. For example, a table or variable may offer data on all responses that checked “yes” or “no” to question 8 for Hispanic, Latino, or Spanish origin. This would include all responses to Question 8, regardless of which racial category was picked for question 9. If you use a table or variable structured this way, understand that it will include all racial categories as well in that data. Likewise, if you choose a table or variable that only address the race question, it will include all responses to question 9 regardless of how they answered question 8.
-
Second, data is available that separates the Hispanic or Latino Question 8 “yes” responses from the Question 9 racial responses. This results in a table with Hispanic “yes” as one variable, and then racial categories for all the “no” responses. So, where some tables or variables would say “White,” these tables or variables would say “Not Hispanic or Latino, White Alone.”
In most instances, FHWA recommends analyzing race and ethnicity census data using tables and variables as described in #2: Hispanic or Latino “yes” answers with “Not Hispanic or Latino” racial group. This will ensure the analyst does not accidentally double-count, potentially reporting a total > 100% of the individual responses.
Geography
When analyzing data from the Census, it is important to understand how the data are presented geographically. The Chart below shows the different geographical entities used in the census.

The geographic unit you choose for your analysis will vary based on what it is you are analyzing. Typically, though, for project reviews you will be looking at block groups and tracts. And for larger reviews, of statewide programs for instance, you may wish to use a larger geographical entity such as a county.
As the smallest unit the Census offers, with populations as low as zero, the use of blocks can be tricky. They are useful for granular analysis of locating populations but comparing one block’s population to another’s with a percentage can be misleading. For example, if two blocks are 50% Hispanic, one block could have 300 Hispanic persons out of 600 and the other 1 out of 2.
American Fact Finder
American Fact Finder, formerly available at https://factfinder.census.gov/, was the primary source for gathering the relevant data from the US Census, but the Census Bureau discontinued the site on 3/31/20. The Bureau intends that users find their data primarily on a new website: https://data.census.gov.
Data.Census.Gov
This new website is intended to replace FactFinder for all data requests from the US Census. It includes most archived and new Census products, and it features most of FactFinder’s functionality with some new resources for data scientists as well.
The next sections will demonstrate how to gather that information. FHWA recommends gathering demographic data from table P2 from the 2020 decennial census and table B03002 from the 5-year American Community Survey (ACS). These tables show the Hispanic or Latino population and the not Hispanic or Latino population broken down by race. Using these tables will avoid some of the issues related to the separate race and ethnicity questions discussed earlier.
Note that the census provides other tables with this structure (Decennial P5, for example), but P2 and B03002 will be a useful start. Also, table names can change between each Decennial census, so note that P9 was the name used for a similar table in the 2010 Decennial census.
Selecting Geographies – Table Search Method
The example below demonstrates how to gather this data through a simple search to download demographic data at the block group level for Baltimore County, Maryland from the 2020 census.
Step 1 – Go to the main page
First, navigate to https://data.census.gov, scroll to the middle of the page, and click  .
.
Step 2 – Choose the data table
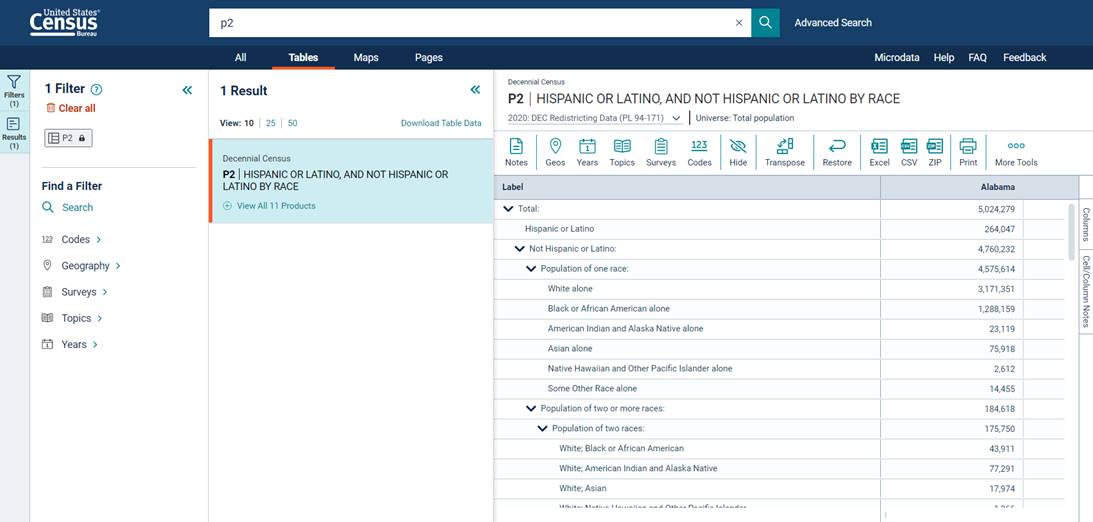
This is the main page for accessing U.S. Census data. There are several ways to get data, but this guide will start by searching for a table by name. At the top of the page, click on the text box that says Search at the top of the page. Type “P2” (without quotes) and click  . It may take a moment for the page to load.
. It may take a moment for the page to load.
Step 3 – Choose the geography
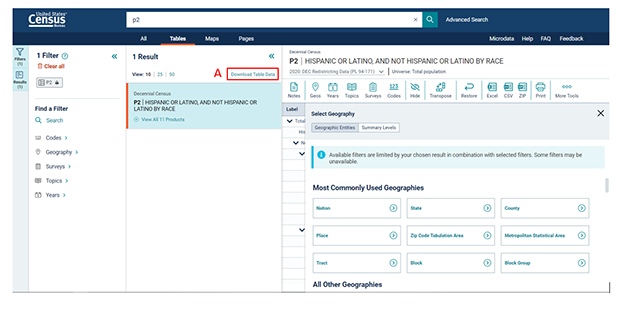
Most tables will show data for the entire country by default, so let’s change our geography first. Click  near the top of the page. From here, the page will display a new layer with commonly used geography options.
near the top of the page. From here, the page will display a new layer with commonly used geography options.
While Block offers the most granular population data, let’s view the next level out by clicking  . Next, you will select the state. Scroll down and click on Maryland, then click on Baltimore County, Maryland. If you knew which tract you wanted, you could choose it here, but for now let’s click All Block Groups within Baltimore County, Maryland, then click
. Next, you will select the state. Scroll down and click on Maryland, then click on Baltimore County, Maryland. If you knew which tract you wanted, you could choose it here, but for now let’s click All Block Groups within Baltimore County, Maryland, then click  (A) to make viewing the data easier.
(A) to make viewing the data easier.
Step 4 – Download the data
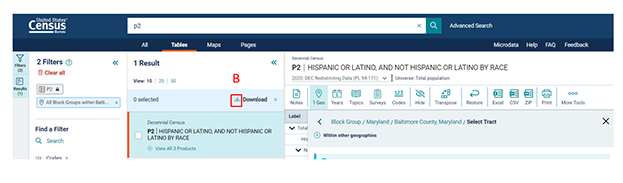
Once you click  , the page will display a new layer of information. You will select the P2 table by clicking
, the page will display a new layer of information. You will select the P2 table by clicking  . The checkmark in the box indicates the data selected. To download the data, click
. The checkmark in the box indicates the data selected. To download the data, click  (B) and a new screen will pop-up.
(B) and a new screen will pop-up.
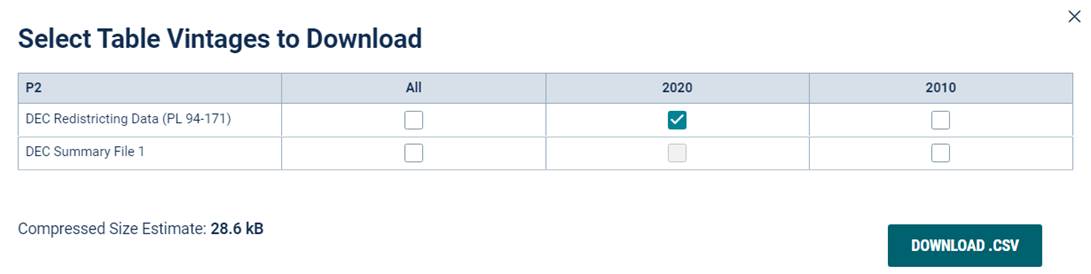
Click  to download the zip (compressed) file to your computer.
to download the zip (compressed) file to your computer.
Step 5 – Open the data file

Find and open the zip file you downloaded to your computer. Many web browsers will save files to the Download folder on your computer by default. Open the zip file, which in this example is called DECENNIALPL2020.P2_data_with_overlays_2022-02-17T101557.csv. (Note that the file name changes according to the data requested and the date.)
This “csv,” or comma separated values, file will open in most spreadsheet programs like Excel. The “metadata” file will display a list of all variables in the table with descriptions but no other data. The “data_with_overlays” file will have the variable names, description, and the data.
Step 6 – Analyzing the data
With the data downloaded, it can be modified and analyzed. For example, Excel can word wrap the column headers to make them easier to read. Unneeded columns can be deleted. Percentages can be calculated for all of the race/ethnicity categories. With the “GEOID” column, you can match the data with geographic information system (GIS) programs and other mapping resources. To create population percentages, multiply the total population with the targeted demographic group, such as “Not Hispanic – Asian Alone.”
FHWA has created a macro that, when enabled, can make reading the data easier. It will generate percentages and summarize the area under review after downloading census information. If you would like access to this tool, please email CivilRights.FHWA@dot.gov.
Selecting Geographies – Map Method
An alternative to selecting the geographic area from the Customize Table menu is to use the map selection method within data.census.gov. This can be useful for narrowing a search to fit a smaller or more specialized area. This example will demonstrate how to use the map in Data.Census.Gov to select a P2 table with census block groups in downtown Baltimore, Maryland.
Step 1 – Select the table
Search for the P2 table in the top search bar like the prior example. Instead of staying in the Tables section, click  located on the dark blue ribbon under the Search box. Once clicked, a blank map of the United States is displayed.
located on the dark blue ribbon under the Search box. Once clicked, a blank map of the United States is displayed.
Step 2 – Select the geography
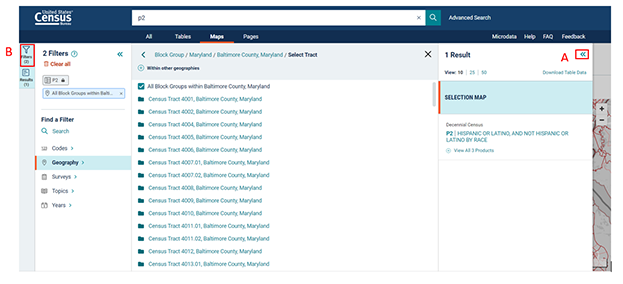
Most tables will show data for the entire country by default, so let’s change our geography first. Click  on the left side. From here, the page will display a new layer with commonly used geography options.
on the left side. From here, the page will display a new layer with commonly used geography options.
While Block offers the most granular population data, let’s view the next level out by clicking  . Next, you will select the state. Scroll down and click on Maryland, then click on Baltimore County, Maryland. If you knew which tract you wanted, you could choose it here, but for now let’s click All Block Groups within Baltimore County, Maryland.
. Next, you will select the state. Scroll down and click on Maryland, then click on Baltimore County, Maryland. If you knew which tract you wanted, you could choose it here, but for now let’s click All Block Groups within Baltimore County, Maryland.
Step 3 – Adjust the screen
At this point you can make some adjustment to your screen. You can close the filters on the left by clicking  (A). To reopen the Filters section, simply click
(A). To reopen the Filters section, simply click  (B).
(B).
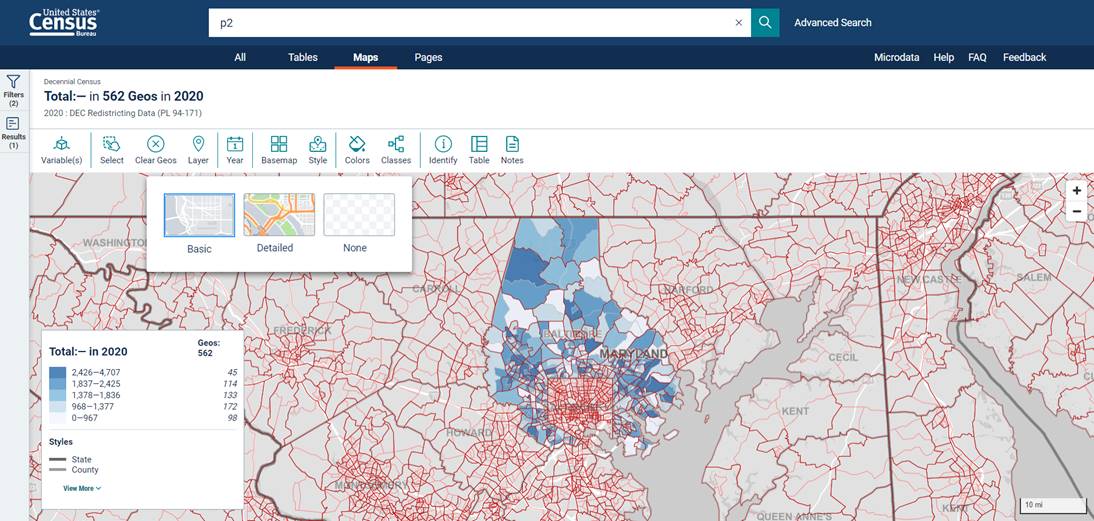
You can also change the basemap, or the underlying map of the United States. The default map is grey and not detailed (as seen above). To change this, click  on the top of the screen. Then, select Detailed for a colorful basemap detailing more streets and other names.
on the top of the screen. Then, select Detailed for a colorful basemap detailing more streets and other names.
Step 4 – Clear geographies to pull specific data
If you want data from specific block groups or areas, you will need to clear the geographies first.
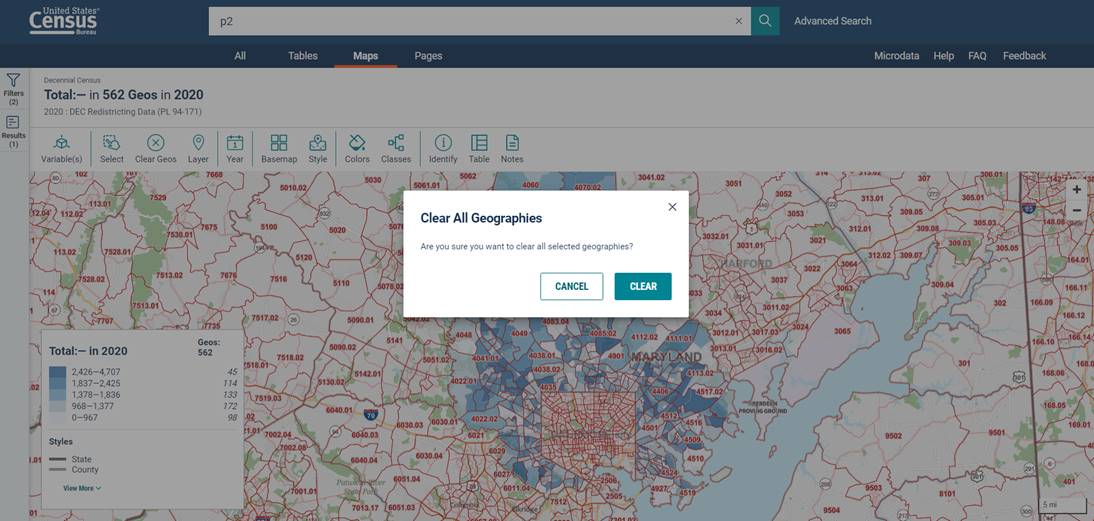
Click  on the top of the screen. When the warning message pops-up, click
on the top of the screen. When the warning message pops-up, click  . The map is now ready for you to select the areas you want to pull data from.
. The map is now ready for you to select the areas you want to pull data from.
Step 5 – Select areas to explore
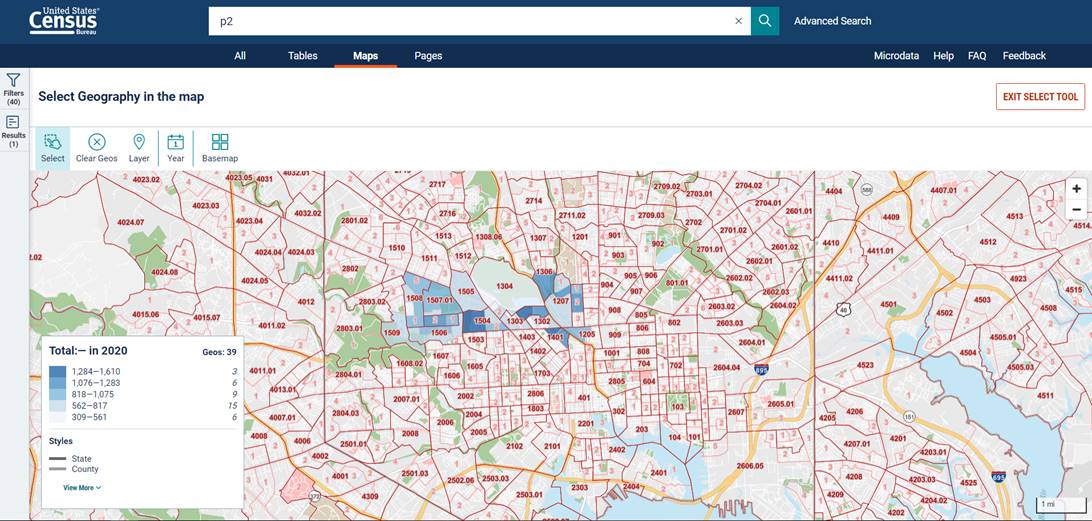 Â
Â
The map will display numbered outlines of the census tracts in the area. As you zoom in, you will see the block groups pop-up in light red. Click  in the upper-left, then click and hold your curser on the map to draw a rectangle around the area you want to explore and unclick when finished. After a moment, the map will show the data for the selected area in the form of a heat map. Drawing another box will select additional block groups for the table. There is a limit to the number of selections allowed by the system, which varies by type. For block groups, the system only allows ~ 1000 selections. A message will appear when you’ve exceeded the limit. If this happens, simply download your table, clear your selections, and select your additional geographies to download in its own table.
in the upper-left, then click and hold your curser on the map to draw a rectangle around the area you want to explore and unclick when finished. After a moment, the map will show the data for the selected area in the form of a heat map. Drawing another box will select additional block groups for the table. There is a limit to the number of selections allowed by the system, which varies by type. For block groups, the system only allows ~ 1000 selections. A message will appear when you’ve exceeded the limit. If this happens, simply download your table, clear your selections, and select your additional geographies to download in its own table.
If you accidentally select an undesired location, click  in the upper-left and all the selected areas will go away. If you choose too large of an area, nothing will happen. You will need to break the area into smaller pieces and select it a little at a time. When you are finished selecting, click
in the upper-left and all the selected areas will go away. If you choose too large of an area, nothing will happen. You will need to break the area into smaller pieces and select it a little at a time. When you are finished selecting, click  again or
again or  to close the tool.
to close the tool.
Step 6 – Download the selected data in a table
When you are ready to pull the data from the selected areas of the map, you can download the data in table form. Reopen the Filters screen by clicking  on the far left side of the screen, then
on the far left side of the screen, then  . Once you click , a new layer of information will display. You will select the P2 table by clicking
. Once you click , a new layer of information will display. You will select the P2 table by clicking  , then click
, then click  to begin downloading.
to begin downloading.
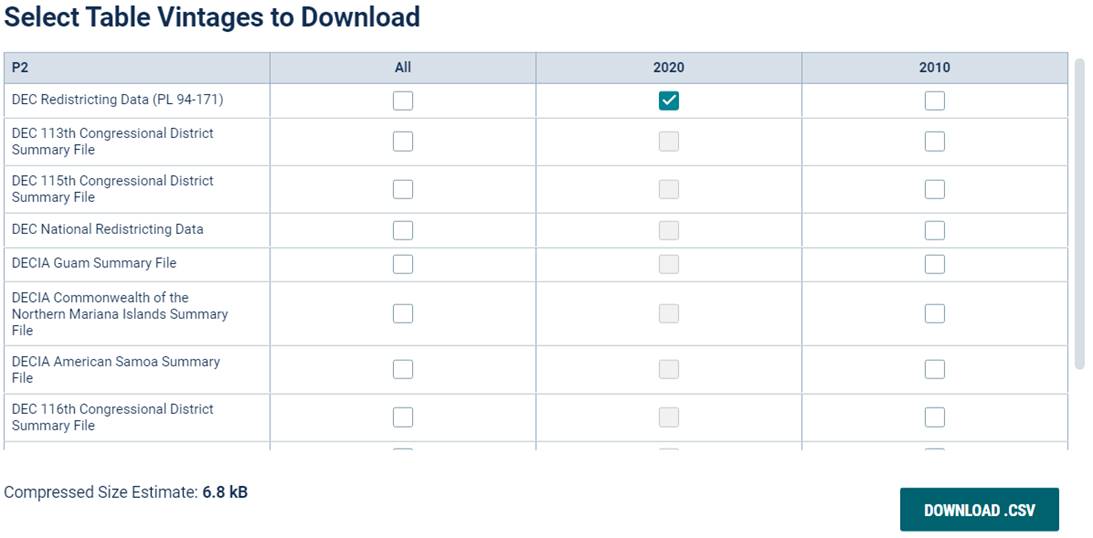
Before the download will begin, the site will ask you to confirm the data source. Make sure the DCE Redistricting Data is selected and click

to download the zip (compressed) file to your computer.
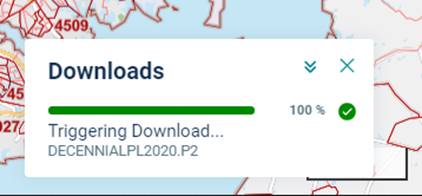
You will see a Downloads progress bar toward the lower right side of your screen. If the progress bar shows 100%, but you don’t see the file in your Downloads folder or at the bottom of your screen, click  again.
again.

