






Investment in the information source cannot be regarded as a one-time event. To remain a viable long-term resource for the industry, the information source requires a thoughtful and proactive approach to its management. This will ensure that the owning organization is able to manage the data resources according to appropriate levels of performance, protection, availability, and cost.
Establishing a high quality and high profile information source would require significant investment in order to provide relevant and useful information on project outcomes for P3 and non-P3 projects. It is envisioned that the process would include the following components:
Important aspects of the work flow would include the Plan, Collect and Assure phases, during which the planning, collection and quality assurance of the project-based information will occur prior to being entered into a database and made available to the public through the online portal. High-level specifications for the on-line portal are discussed in Chapter 4.
The data management plan will be a critical aspect of the information source. Planning for data management would involve answering several questions about how the data would be gathered and used to populate the information source. These questions include:
Questions regarding data availability are addressed in Chapter 3 of this discussion paper. The larger question underpinning the data management plan involves determining who would be responsible for data collection and the associated schedule and budgetary needs. While the information platform described in Chapter 4 suggests that import of data into the information source may be facilitated with the help of templates, the structure of the entity or entities responsible for collecting information and importing it into the information source could take three potential forms:
Figure 3. Distributed Responsibility Data Management Plan
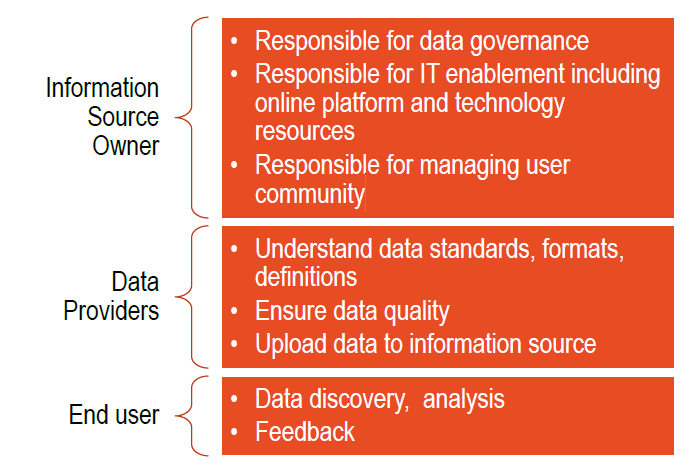
Source: WSP | Parsons Brinckerhoff, 2017
View larger version of Figure 3
| Information Source Owner |
|
|---|---|
| Data Providers |
|
| End user |
|
Figure 4. Total Ownership Data Management Plan
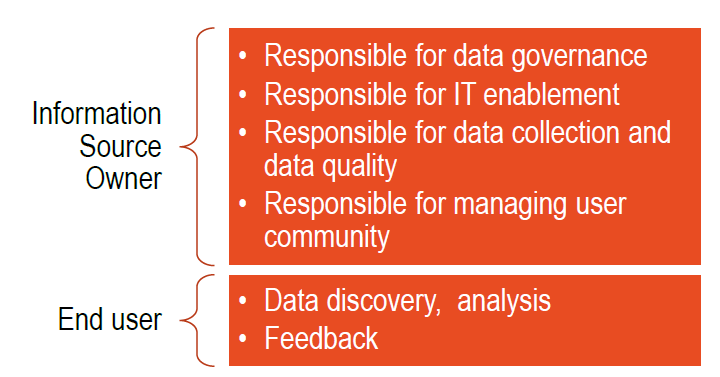
Source: WSP | Parsons Brinckerhoff, 2017
View larger version of Figure 4
| Information Source Owner |
|
|---|---|
| End user |
|
Figure 5. Hybrid Data Management Plan
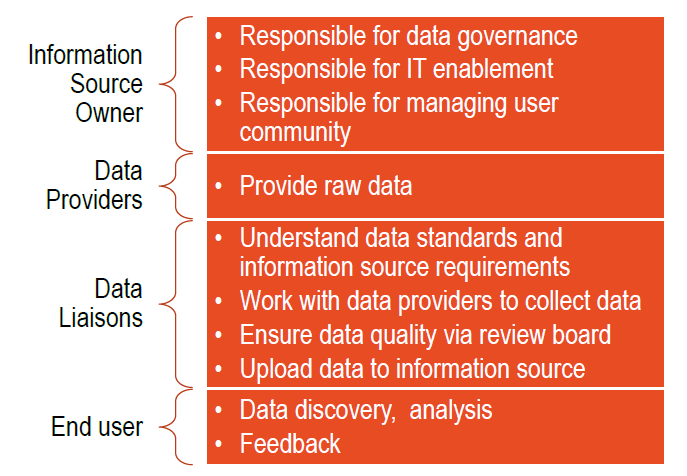
Source: WSP | Parsons Brinckerhoff, 2017
View larger version of Figure 5
| Information Source Owner |
|
|---|---|
| Data Providers |
|
| Data Liaisons |
|
| End user |
|
The selection of a final data management approach should involve careful deliberation of the pros and cons of each option considered. The requirements of the information platform (relational database and file management system), the data collection, quality reviews and maintenance strategies, and roles and responsibilities of the various parties involved will flow from the selected approach. In addition, given that the information for each project in the database will be developed over several years, the management of the database is a long-term activity. Therefore, data collection, population and quality assurance will be on-going, long-term activities involving multiple parties.
For the purposes of this paper, data collection is defined as a coordinated set of activities that begins with identifying the key points of contact at the data sources (identified in Chapter 3), making data requests, receiving and collating data, and moving it to the next step of quality assurance and upload. There are two types of data needed to complete the information source: 1) primary data, i.e., data that are available from the data sources in a form that can be readily consumed by the information source; and 2) data discovered through secondary research such as interviews, questionnaires, detailed project reviews and other specific information elicitation techniques. A majority of the data for Tier 2 is expected to fall in the latter category. Two types of actors will be needed to gather the necessary information, as discussed below.
Primary Data Providers: For an overwhelming set of the information needed to address the core questions, the primary data providers are project sponsors/owners. The USDOT and FHWA are also valuable sources of project information since they collect some of the desired information as part of their monitoring and oversight activities. In a few instances, for DB and P3 projects, the DB contractor or private partner are also responsible for generating and reporting some of the primary data elements. Examples of such data include legislative information, agency capacity and policy, asset condition and operational (performance) information. All data incorporated into the information source should undergo reliability tests (as explained below in section 5.1.3).
Secondary Data Providers (including Research): As noted above, a majority of the data elements for Tier 2 require research that is attuned to the needs of the information source. This would likely involve additional interviews with specific parties within the project owner/sponsor and the identification and review of key internal and published project documents. While project sponsors/owners or their contractors and private partners technically have access to their own information, they will need to re-analyze it in light of the needs of the information source to make such data available in appropriate formats and with common metrics. Regulatory agencies such as the USDOT or FHWA routinely perform research on some data elements and have many datasets or project-specific reports that could provide helpful input to the information source. Other interested industry stakeholders might have similar information. However, it is expected that additional effort would be needed to research and mine the requisite information for the information source. Stringent protocols and reliability tests will be needed to maintain the quality of the data incorporated into the information source over time.
The online information source will include some data metrics that are robust and others that are more descriptive and may require judgement and interpretation by the team assembling and maintaining the information source. The information source could create an illusion of consistency by inappropriately including disparate data into binary or other constrained categories.
Data quality assurance is an ongoing activity lasting at least as long as the information source is active. Data quality assurance is required when data is uploaded to the information source. Two levels of quality assurance are recommended. The first step would be to validate the data fields being uploaded to the information source to ensure that they are consistent with the backend database in terms of units, maximum and minimum value, type of data (e.g., text or numbers), etc. This could be an automated process using a validation checker that could be made available as part of the online information platform described in chapter 4. Once the validation checks are completed, the data could be admitted into the database with lowest level of quality assurance certification attributed to it along with a version control. A data completeness check could also be incorporated as an automated process to review the number of expected fields to be completed at a given project stage versus the number of fields for which data is actually populated.
A second, more laborious and manual data checking process is also recommended to assure the usability and competency of the data. This review would entail ensuring that the data submitted for publication in the information source passes the test of reasonableness to be valuable to end users. Reasonableness checks could be performed on all aspects of the information submitted, but should focus mainly on the core questions that the information source is designed to address. The checks could encompass reviewing information on costs, schedule, financial performance, and quality (during design and construction and in-service). The intent would be to ensure that the reasonableness checks are directly related to the data fields being collected (or their derivatives) and that their coverage is comprehensive and encompasses the entire information source. It is possible that the information source assigns a confidence level to the data published using an arbitrarily selected, but well explained, rating scale.
Examples of questions to be asked to check the reasonableness of the submitted data could include:
If the answers to any of these questions (or other similar ones formulated during the review process) are questionable, secondary research, including formal outreach to the data sources to verify data accuracy, may be necessary. Triangulation and replication tests provide the highest degrees of reliability and validity. Any verification processes would be formalized through proper communication protocols, including feedback and data reconciliation reports during the operational phase. Any data that is reconciled would need to be updated and the "raw" data source cleansed, with appropriate versioning and re-certification steps occurring to ensure the quality of the new information.
The responsibilities for data collection will align with the approach chosen for the data management plan. If Approach 1 were chosen, the project data originators would become responsible for primary and secondary data collection as well as data completeness, accuracy and long-term population. The information source owner would provide the platform, data standards and IT enablement for uploading and use of the data. In Approach 2, data collection and quality would be the responsibility of an "outsourced" entity, which would work in cooperation with the information source owner to populate and maintain the online information source. In Approach 3, primary data collection would be assigned to the data originator, with secondary data collection outsourced, and the data quality assurance function would be housed with the information source owner along with the IT enablement function.
No matter which approach is selected, it will be important for the parties responsible for assembling the information source to engage with state and local project sponsors to obtain ongoing data updates. The information source would also benefit from a strong initial impetus focused on creating a robust online platform and creating a critical database of project-related information. This is important to understand the value proposition created by the information source, finalize details of the management plan, and attract agency participation and secure funding for the long-term sustenance of the information source. Initial seed funding for the information source could be provided through a pooled-fund study using state DOT research monies from multiple states, through the national cooperative highway research program, or by the U.S. Department of Transportation.