U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-06-033
Date: August 2006 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Task Analysis of Intersection Driving Scenarios: Information Processing BottlenecksPDF Version (4.01 MB)
PDF files can be viewed with the Acrobat® Reader® SECTION 2. METHODSThis section describes the methods used to conduct a task analysis for each of seven urban signalized intersection scenarios. The section includes the methodology for selecting the scenarios and conducting the various analyses in this report including the task analysis tables, segment timelines, segment analyses, and scenario-wide analyses. Scenario selectionThe first step in this effort was to develop a list of candidate scenarios. This initial list covered different combinations of intersection control-type (e.g., stop sign-controlled, signalized), configuration (e.g., three-leg, multilane), location (e.g., urban, rural), and maneuver (e.g., left-turn, straight through). These scenarios were prioritized based primarily on crash data, but also for potential involvement of pedestrians and cyclists, and if countermeasures existed to address related safety issues. It became apparent from this preliminary analysis that urban signalized intersection scenarios tended to have a higher priority than other scenarios. Based on this information and in consultation with the Federal Highway Administration (FHWA), a decision was made to limit the task analysis to urban signalized intersections. Scenarios were developed for the following maneuvers at urban signalized intersections:
In addition to the basic maneuvers and conditions, some complicating factors (e.g., dilemma zone at yellow light change, lane changes) were included in some scenarios to increase the overall scenario difficulty and introduce a greater variety of driving elements. All scenarios were based on the same four-lane (two lanes in each direction), four-leg intersection. Two-lane or three-leg configurations were not used because they did not provide significant information beyond what was already available in the baseline configuration. Also, focusing on a common configuration allowed the procedures to be simplified. Scenario Analysis ComponentsEach scenario analysis has several parts:
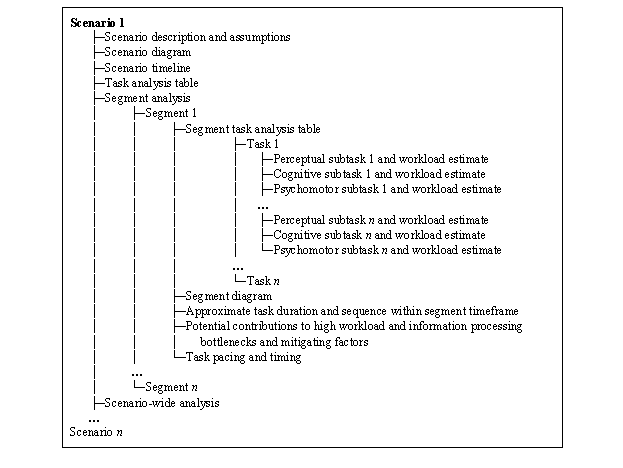
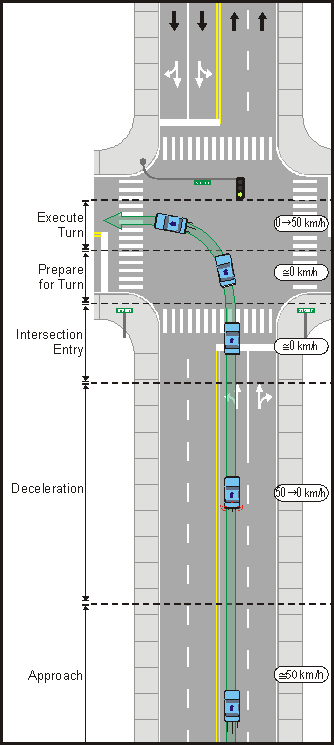
An outline diagram showing the organization of these components is shown in figure 1. Also, these components are described later in more detail. Figure 1. An outline diagram showing organization of components of each scenario analysis. Scenario Description and AssumptionsFor each scenario, an overall description was provided that defined the basic layout and key assumption of the scenario (figure 2). The assumptions typically specified the intersection layout, traffic volume, and other conditions (e.g., actions of other drivers) that were relevant for determining the specific tasks involved and the scenario timelines. Included in the scenario description is a diagram that depicts the layout, basic infrastructure design, and key features of the scenario. This diagram also demarks the general regions associated with each scenario segment. In the scenario diagram and also in the segment diagrams, the subject vehicle is always shown in blue, while other vehicles are always shown in white. The scenario diagram also shows the hypothetical path of the target vehicle (green arrow) and approximate speed in kilometers per hour (km/h) during each segment. Scenario TimelineFor each scenario, an approximate timeline showing the key temporal milestones was calculated based on vehicle kinematics. The milestones represented key events that can be pinpointed in time based on scenario dynamics and assumptions. These milestones were used to make judgments about the pacing of tasks within scenario segments (e.g., forced-paced versus self-paced), in addition to providing a basis for the overall sequencing of certain tasks. Appendix A provides the results of this analysis, including the equations and assumptions used to calculate each milestone. The kinematic features of each scenario, which determined the temporal and physical placement of the milestones, included acceleration and deceleration rates, reaction times (RT), sight distances to the intersection, vehicle gap distances, and stopping distances. The scenario dynamics and any associated assumptions were based on established values and guidelines described in the human factors literature and roadway design manuals, such as the American Association of State Highway and Transportation Officials (AASHTO) Green Book (3) or the Manual on Uniform Traffic Control Devices (MUTCD).(4) Also, distances traveled and times of travel were calculated using standard motion equations found in any general physics text (e.g., reference(5) page 20, shows these equations). One notable point is that many scenarios included segments that had an interval with a variable time component, which represented intervals that either were long enough to effectively provide unlimited time to perform tasks or of a duration that was determined external to vehicle kinematic factors (e.g., waiting for lead vehicle to turn). Task Analysis TableConsistent with established procedures for conducting task analyses (6,7) and with past task analyses conducted by the contractor's staff,(8) the task analysis was developed using a top-down approach that successively separated driver intersection activities into scenarios, scenario segments, tasks, and subtasks. These components are presented in a single task analysis table organized by segments, tasks, and subtasks. Figure 2 shows an example scenario diagram with key assumptions.
Scenarios were specified in detail with the assumptions about the intersection configuration, traffic conditions, and other complicating factors (e.g., level of traffic flow, additional maneuvers or tasks) defined in advance. The task analysis strictly addressed the defined scenario and did not provide a grand overview of all possible situations or outcomes; however, several of the scenarios contain components (e.g., lane change) or specific tasks that are general enough to be extracted and applied directly or with modification to other related intersection situations. Each scenario was initially divided into a series of three to six consecutive segments, with each segment generally representing a related set of driving actions. The criteria for defining a segment was not fixed; however, a segment typically involved a group of actions geared toward a common goal or driving objective (e.g., decelerating, executing a turn). Differences in speed characteristics were also used to define segments. The reason for using speed was that different speeds are associated with different rates at which information passes by as well as different time constraints. Note that the demarcation into segments was done primarily for convenience of analysis and presentation; segmentation was not performed to imply that the overall driving task could be neatly carved up into discrete stages. In particular, several tasks (e.g., monitoring for hazards) cut across multiple segments. In these cases, crosscutting relationships were represented by separately including these tasks in each of the segments in which they were involved. Within each segment, individual tasks that drivers should or must perform to safely navigate the intersection were identified. The tasks represented information that needed to be obtained, decisions that needed to be made, or actions that needed to be taken over the course of the segment. Note that in listing these tasks, the assumption was not that all tasks would be exhaustively performed during a segment; instead, the list was taken as an indicator of what drivers should do, with the understanding that some or many drivers most likely would perform only a subset of the tasks depending on the time available. The tasks were described at an intermediate level of detail. More specifically, most of the tasks could have been further decomposed into a greater number of finer-grained tasks, but instead they were deliberately left at a more general level. This level of detail was chosen because it was compatible with the tools available for assigning workload estimates to the tasks (discussed later) and because it was general enough so that the relative sequence of tasks was mostly clear. In contrast, with a fine-grained level of detail, determining the sequence of the many resulting tasks would have been impractical and arbitrary. Segment tasks were further divided based on the information processing elements (perceptual, cognitive, and psychomotor requirements) necessary to adequately perform each task. Each task had a subtask defined for each of the information processing domains, and these were used to derive the task workload estimates in the segment analyses (discussed later). The primary source of information for segment tasks was the comprehensive driving task analysis conducted by McKnight and Adams;(9) however, in several cases, other sources such as Tijerina, Chovan, Pierowicz, and Hendricks,(10) which are derived from McKnight and Adams,(9) were used to organize the tasks into segments because they provided a more situation-specific distillation of the relevant task elements. Also, where applicable, additional task analyses and other research were used to supplement the information from McKnight and Adams.(9) For the most part, the McKnight and Adams (9) task analysis and other research provided information about which tasks were involved in a segment/scenario, but they did not give complete information about the specific information-processing subtasks. To determine this information, the researchers identified details about the information-processing subtasks and any other necessary information based on expert judgment and other more general sources of driving behavior and human factors research.(11,12,13) Table 1. Information sources used in the task analysis.
Segment AnalysesEach segment was separately analyzed in several different ways to provide information about potential information processing bottlenecks. The resulting information sources are described in the following text and shown in figure 3 (the numbers in the list correspond to figure 3 numbers):
Figure 3. Two-page layout of segment analysis showing key components. 1. Task workload estimate tables-Duplicate the relevant sections of the task analysis tables with the addition of workload estimates for each of the information processing subtasks. These tables provided source information for evaluating the amount of workload that each task might hypothetically impose on a driver in the scenario. Workload was estimated using a workload estimation chart used by Campbell and Spiker(8) for helicopter pilots, and it was modified to reflect the driving environment as shown in table 2. These estimates were based on an ordinal scale that represents increasing workload. For each subtask, the primary subtask component was matched with a comparable task in the workload estimation chart, and the corresponding value was assigned. The mapping between subtask and chart estimation was not always straightforward, and sometimes it required researcher judgment to determine a value. Also, in some cases, complicating factors were present (e.g., degraded visual information) that made the task noticeably more difficult than the chart estimation. In these instances, the workload estimation was incremented by a value of 1 to reflect the increased difficulty, and the change was noted in the table footnotes. To provide some level of validation for the process of assigning workload estimates, a review process was developed for calibrating the workload estimates and the corresponding tasks. More specifically, a panel of three senior researchers reviewed the workload estimates, in a process which involved separately assigning workload estimates to tasks from a pilot scenario. The reviewers then compared their results and came to a consensus on the appropriate workload estimates for each task/subtask. The resulting workload and task combinations served as reference examples for assigning workload estimates to related tasks in other scenarios. Any new or difficult-to-characterize tasks in subsequent scenarios were evaluated using the same review process. One issue that complicated the assignment of workload values was that many driving tasks are routine and have been automatized so that they draw on fewer mental or attentional resources than when drivers first learned to perform these tasks.(14,15,16) To reflect this, the workload estimates would have to be lowered to reflect demands attenuated by automation. Also problematic is the possibility that in some situations, routine tasks may not be performed in a routine manner (e.g., identifying an intersection in an unfamiliar location). Thus, to simplify the allocation of workload estimates and avoid underestimating workload in potentially critical situations, the effects of automat city were considered on a case-by-case basis in the summary of potential complicating or mitigating factors and the scenario-wide analysis. Table 2. Workload estimation chart used to determine workload estimates for each segment task.
2. Segment diagram with distribution of potential information sources - This diagram indicates the general distribution of important information sources for key tasks (dotted blue lines accompanied by blue task number labels). These were derived by broadly outlining likely location of task information with a significant perceptual element in typical intersections. In addition, to provide context for the positioning of the information sources, the diagram also shows the location of relevant roadway furniture and other pertinent information, in addition to the position and status of other nearby vehicles (e.g., if they are braking). 3. Relative timing and duration of segment tasks - This table shows the relative timing and duration of the segment tasks, as indicated by the relative position and width of the bars next to each task in the table. More specifically, scenario segments were divided into four to six intervals representing different time periods in which tasks could occur (the number of intervals was determined based on the need to represent successive tasks as not overlapping in time). The timing and duration estimates were based on the calculated scenario timelines and temporal milestones, logical precedence of the tasks, and whether individual tasks overlapped wholly or in part with other tasks. Thus, tasks with interval bars that precede those of other tasks are assumed to occur before those other tasks, whereas tasks that have bars occupying the same interval are assumed to occur concurrently. Note that just because tasks are shown as taking place concurrently, they are not necessarily performed simultaneously. Rather, these tasks are portrayed this way to denote the situation requires that those specific tasks are to be performed at that particular stage in the segment, regardless of whether the individual driver chooses to perform the tasks simultaneously, sequentially, or skip them altogether. Another aspect of the driving tasks represented by this table is the task pacing. Individual tasks were defined as being either self-paced, meaning that the driver generally has significant control over the timing and execution of task performance, or forced-paced, whereby performance involves task timing and execution that is mostly determined by factors outside of the operator's control.(14) The different types of pacing are indicated by green and orange shading of the timeline bars, which represent self-paced and forced-paced tasks, respectively. 4. Summary of potential contributions to high workload and information processing bottlenecks and mitigating factors - This section summarizes some key factors identified in the other segment analysis components that either potentially contribute to information processing bottlenecks or act as mitigating factors. Typical contributing factors included concurrent tasks, several tasks with high workload estimates in a particular information processing domain, high time pressure, and forced-pacing of key tasks. Typical mitigating factors included self-pacing of key tasks or key tasks that were routine or likely to be automatic. Scenario-wide AnalysisThe purpose of the scenario-wide analysis was to integrate the different sources of information from all the segment analyses and identify potential information processing bottlenecks associated with each scenario. The general strategy for finding bottlenecks was to identify situations in which drivers are required to perform multiple tasks concurrently. The assumption is that the more tasks that drivers must do at one time or in close temporal proximity, the more likely they are to make errors or voluntarily or involuntarily forgo performing some of those tasks. In addition to the temporal relationship between tasks, another aspect of performance that was considered important was the difficulty level (reflected in workload estimates) of the subtasks within a particular information processing domain. In this case, drivers would be more likely to make errors or skip tasks if the concurrent tasks are more difficult than if they are easy and perhaps automatic to perform. The scenario-wide analysis involved three elements, described later:
1. Graphical workload demand profiles - Provide an overview of the workload demands across each scenario. Workload estimates from all segments were combined into a single scenario-wide workload profile that provides a general indication of where the areas of high workload demands are likely to be. To capture the temporal overlap and overall difficulty of each information processing subtask, information about the temporal sequence of individual subtasks presented in the segment timeline tables was combined with the workload estimates from the segment task analysis tables. Essentially, the separate subtask workload estimates for all tasks that are active or in play during a segment interval were added together to provide a general indicator of the aggregate workload demand at a particular time.[1] Two different workload profiles were generated for each scenario. The first indicated the total estimated workload rating for all tasks. It provided a measure of the overall workload during the scenario. The second profile indicated the average estimated workload per task for each scenario segment. It was essentially the total segment workload divided by the number of tasks that were active during a particular interval, and it generally represented how demanding the individual tasks in a segment were. For example, high levels of total workload can result from either having many tasks or from having fewer but more-demanding tasks; this profile indicated the extent to which each situation was true. One point worth mentioning is that task pacing (self-paced or forced-paced) can have an effect on the difficulty of a particular subtask by affecting the time available to perform various tasks. Although task pacing information was not directly taken into account in the workload estimates, intervals in which key tasks were forced-paced were indicated on the demand profiles (shaded orange). This information was included to provide some additional context for identifying potential information processing bottlenecks. An important consideration, when taking this approach, is the question of how different tasks potentially interfere with each other. As part of our analytical efforts, we considered a Multiple Resource Theory (17, 18, 19) perspective that focused on interference between tasks that shared the same resources, such as two concurrent visual search tasks. The primary implication of this approach was that workload ratings across information processing subdomains were kept separate in the analysis. Note that there were significant constraints on how resource limitations could be applied to the current analysis. In particular, because driving is generally self-paced, it is difficult to identify clear instances where two tasks that draw on the same resources must necessarily overlap because drivers can delay conducting many tasks until there is time available to do so. Thus, for the most part, potential resource conflicts were addressed only on a general level by identifying them in the potential contributing factors section, discussed later. The exception was in instances where resource-conflicting activities were forced-paced and drivers clearly had insufficient time to delay performing key tasks (e.g., during the decision to proceed when the light just turns yellow). In this case, tasks that must be sequential because they draw on the same resources (e.g., looking at two different locations in the driving scene) were shown as concurrent to represent the likely possibility of interference between tasks and the fact that drivers are likely to skip some of the tasks. This pattern shows up as higher combined workload profile levels, discussed later, than would have otherwise occurred if this approach had not been taken. 2. Table of key information processing issues - Groups key indicators of potential bottlenecks for each segment into a single table. The elements represented in this table include peaks in the workload demand profiles, information about task pacing, and key factors identified in the potential contributing and mitigating factors of the segment analyses. 3. Description of key bottlenecks - Describes the nature of key bottlenecks for each segment with a potential problem. In addition, it describes the key factors underlying the potential bottleneck. LimitationsIt is important to acknowledge the inherent limitations of this work at the outset. This work was not designed to provide a definitive description of intersection driving; rather, it was an analytical activity with limited resources. It was just one part of a multipronged approach designed to assess the potential effectiveness of intersection countermeasures. As such, the most significant limitation is that this is an analytical and not an empirical research effort. In particular, no data were collected either to guide the identification of tasks and their temporal relationships, or to validate the results. Instead, the tasks were taken primarily from the comprehensive task analysis(9) and other supporting sources in table 2; however, this task analysis(9) was also an analytical exercise based on the opinions of a committee of driving experts whose primary goal was to provide information to develop driver training and testing programs. This research is also limited because it relies on the judgment of the primary authors for several decisions about the inclusion of tasks, the sequence and allocation of tasks within segments, and the assignment of workload estimates. Although the authors have extensive experience in human factors, cognitive psychology, and driving research, various decisions about scenarios and included tasks may be biased by the driving experiences of the authors. To counter this potential problem, internal and external reviews (involving FHWA reviewers) were conducted to serve as a reality check on various aspects of the scenarios and related assumptions. Another limitation of this research was that providing a sufficient level of detail in the tasks analysis required that the scenarios be specified to a relatively high degree with fixed assumptions about the scenarios. This requirement not only limited the generalizeability of some of the scenario elements, but it also required that many assumptions be made regarding a variety of aspects in each scenario. To the extent possible, attempts were made to justify assumptions based on logic, existing data, or constraints arising from the scenario kinematics. In some instances, none of these approaches could provide a clear basis for certain assumptions; as a result, assumptions became arbitrary. These instances are discussed in the task analysis as they occur. Another limitation is that the general self-paced nature of most driving tasks and the corresponding control that drivers have over task sequencing makes it difficult to conduct detailed analyses of resource conflicts. Even though the task organization scheme used in this analysis (breaking scenarios down into segments) seems to lend itself to this type of microlevel analysis, the segment divisions are artificial, especially in situations where segments run together (e.g., Approach to Decision to Proceed, or Approach to Prepare for Lane Change) and do not necessarily reflect how drivers actually group tasks together. In addition, because driving is generally self-paced, tasks are likely to be displaced into other segments when time or resource constraints are encountered. Consequently, this temporal variability limits the degree to which it is possible to analyze direct resource conflicts between individual information processing subtasks (e.g., concurrent viewing of separate roadway elements), because in all but the most time-limited situations, drivers control if and when certain tasks are performed; thus, these conflicts were treated at a general level. Potential conflicts were identified, but with a few exceptions (e.g., very time-limited situations). No special cost or penalty was attributed to these situations. A final important limitation is that the workload ratings are ordinal, which constrains what conclusions can be drawn from the workload profiles. This issue was discussed earlier; however, it is worth reiterating that the ordinal workload estimates lose meaningfulness when summed. Considering that the purpose was not to obtain totals that represented absolute workload values, but rather to identify intervals in which the workload demands were generally higher than other intervals, this limitation still allows some useful conclusions. The main point is that caution must be taken when basing results solely on the workload profiles, and a more appropriate approach, which we have tried to take, is to find instances in which multiple factors (e.g., forced pacing of tasks, short time budgets, and high workload) converge to indicate potential information processing bottlenecks. 1Although the underlying workload estimate scales are based on ordinal values, which lose meaningfulness when summed, our purpose was not to obtain totals that represented absolute workload values, but rather to simply identify intervals in which the workload demands were generally higher than other intervals. The underlying logic is that intervals with a greater number of tasks or with more difficult tasks, or both, should be more difficult (higher total) than intervals with fewer tasks or less difficult tasks. Back |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||