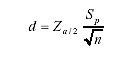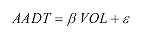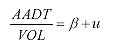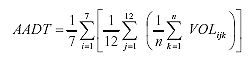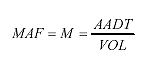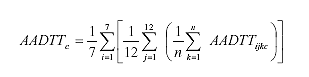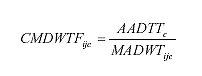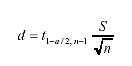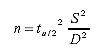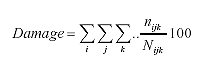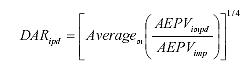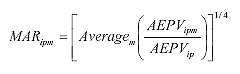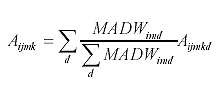U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-05-079
Date: May 2006 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Optimization of Traffic Data Collection for Specific Pavement Design ApplicationsChapter 1. IntroductionObjectiveTraffic loads are an essential input to the pavement analysis and design process. In the past, the effect of traffic was aggregated into equivalent single-axle loads (ESALs) and input into regression-based pavement performance equations. The NCHRP 1-37A design guide(1) characterizes traffic in terms of axle numbers by type and their load frequency distribution (i.e., axle-load spectra). This is a significant improvement over past methods because it allows a mechanistic pavement design approach. It involves computing the pavement structural responses to load (i.e., stresses and strains), translating them into damage, and accumulating the damage into distress and reduced pavement performance over time. Traffic data collection is carried out by a combination of data acquisition technologies, including WIM systems, AVC, and ATR. Typically, traffic data unavailable at a pavement design location are borrowed from other data collection sites that exhibit similar traffic loading and classification properties. The data coverage of traffic data acquisition systems can vary widely from continuously operating to simple 48-hour (h) (or less) data coverage. Even for continuously operating data acquisition systems; however, data coverage may be limited by system malfunctions. These are detected by performing a number of data QC checks. This technology has evolved significantly in response to the needs of the LTPP program.(2) It is typically based on the repeatability of certain traffic patterns (e.g., the distribution of the gross vehicle weight of five-axle semitrailer trucks is used for WIM load data QC). Data that fail to pass these QC tests are considered suspect and should be excluded from the data coverage of these systems. Hence, there is wide variation in traffic data availability and time coverage between pavement design sites. The challenge at hand is to determine the combination of traffic data acquisition technology and the time coverage required for particular pavement design situations. This issue needs to be addressed in light of the sensitivity of the pavement design and performance analysis to the level of traffic data input. The objective of this study is to resolve this problem. A comprehensive approach is used for establishing the relationship between traffic data collection efforts (e.g., combination of traffic data acquisition technologies and length of time coverage) and the variability in the predicted pavement life using the NCHRP 1-37A design guide. Extended-coverage WIM data are used from the LTPP database to simulate these traffic data collection scenarios. Report OrganizationThe report is organized in sections that address each of the tasks identified in the request for proposals (RFPs):
Note that task 3 as described in the RFP involved submission of an interim report. Those findings were incorporated throughout this final report. Literature ReviewThe literature review focuses on two main areas:
In carrying out this review, emphasis was placed on the methodologies used for estimating traffic-load data as described in the 2001 Traffic Monitoring Guide (TMG)(3) and the recently completed NCHRP 1-39 study,(4) as well as the handling of traffic data input to the NCHRP 1-37A design guide.(5-7) The following paragraphs offer a summary of the literature reviewed. Early work by Ritchie and Hallenbeck(8) described the relationship between sampling effort in terms of the number of weekdays of continuous ATR data available and the accuracy in estimating the average annual daily traffic (AADT). Using the central limit theorem produced the expression in equation 1 for the difference interval d between the true and the estimated AADT: (1)
Where:
Accordingly, the accuracy in predicting AADT increases with the number of days used in establishing the mean. Seasonal factors for each month, denoted by b, were derived using two alterative methods. First, a zero-intercept, regression-based method shown in equation 2 was used: (2)
Where:
Second, a simple ratio-based method shown in equation 3 was used: (3)
Where:
It was rationalized that the second method avoided the problem of heteroscedasticity (a condition where the variance in the regression error e depends on the magnitude of the independent variable VOL); therefore, it was deemed preferable for the first method, and later it was adopted by the American Association of State Highway and Transportation Officials (AASHTO).(9) Statistics for these monthly ratios were calculated for groups of roads in Washington State organized by geographic region and highway functional class. The AASHTO Joint Task Force on Traffic Monitoring Standards proposed the following method for estimating AADT from short-term daily traffic volume (i.e., ATR) counts:
This method is expressed mathematically as in equation 4. (4)
Where:
This approach limits the bias that would result from simply averaging traffic volumes for the days of the year available. In implementing this approach, holidays and the days that precede and follow them should be excluded. The AASHTO procedure is the one recommended by the 2001 TMG. Accordingly, monthly adjustment factors (MAF or M) are calculated as in equation 5. (5)
Where:
Finally, AASHTO recommended an averaging procedure for estimating missing traffic volume data. For example, if the traffic volume for a Wednesday is missing, it can be estimated as equal to the average of the available traffic volumes for the other Wednesdays in a particular month. Similarly, estimating missing vehicle classification data would involve averaging the volume counts by class or groups of similar classes for the same days in the month. Furthermore, missing WIM data can be estimated from the vehicle classification data obtained this way and the frequency distribution of axle loads by axle configuration available for the same days of the month. A Federal Highway Administration (FHWA)-funded study used continuous ATR, AVC, and WIM data from traffic monitoring sites to compute:
The study examines the sensitivity of the computed statistics to various simulated sampling schemes and factoring procedures.(10) Seven factoring procedures were described for computing AADT from ATR (vehicle count) data, which are listed in table 3 in order of increasing accuracy and complexity.(10)
This study recommended that procedure 4 (the CMDW method highlighted in table 3) is a good compromise between accuracy and complexity. This is the same method recommended by the 2001 TMG.(3) Accordingly, equation 6 shows the combined monthly and DOW factor for month i and DOW j at ATR station l, denoted by CMDWFijl. (6)
Where:
In applying this procedure, it is recommended to exclude weekdays close to holidays (e.g., the Friday after Thanksgiving), although these days should be included in computing the AADT. If instead of vehicle counts, conventional axle counts are available, additional axle factoring would be necessary to convert axle counts to vehicle counts. The traffic patterns established from continuously operating ATR sites can be used to compute AADT from short-term volume counts at other comparable sites.(10) Comparable sites are established on the basis of roadway functional class. Short-term counts should be taken over at least a 24-h period and preferably over multiple 24-h periods, although the improvement in predicting AADT from 24 to 48 weekday-h samples was marginal, producing a reduction in absolute error of 1 percent. The procedures described for factoring ATR data to obtain AADT(10) also applies for factoring AVC data to obtain the AADTT by truck class. The essential difference is that the counts are per vehicle class rather than for all classes collectively. A subsequent study examined the effect of the traffic data collection effort and methodology used in obtaining the traffic input necessary for forecasting cumulative ESALs and the resulting difference in pavement life predictions and life-cycle pavement costs.(11) The 2001 TMG recommends collecting traffic volume data through a combination of a limited number of continuously operating reference ATRs and a larger number of shorter duration coverage ATRs.(3) Coverage ATRs should record data over at least 24 h and preferably more than 48 h using systems that summarize the data hourly. These short-duration counts require adjustments to reduce the effects of temporal bias. Adjustment factors are developed for particular months and DOWs by analyzing data from continuously operating reference ATR stations. Data from these stations are combined into groups of similar characteristics, either subjectively (e.g., in terms of geographic location or roadway functional class) or preferably through statistical clustering techniques. Appendix 2-b of the 2001 TMG gives an example of clustering in identifying ATR sites with similar MAFs using the Statistical Analysis System (SAS®) statistical package.(3,12) AVC counts are collected following principles similar to those used for collecting ATR counts. The main difference is that seasonal traffic volume adjustment factors (monthly and daily) are developed for three or four broad vehicle classes (passenger cars, single-unit trucks, single-trailer trucks, and multitrailer trucks) rather than for all vehicles collectively. This is one of the major differences of the 2001 TMG compared to earlier TMG versions (1992 and 1995), and it was introduced to account for the seasonal variation in traffic volume patterns of various classes. These seasonal factors are developed by analyzing data from continuously operating reference AVC stations representing the traffic conditions of the selected roadway groups. These groups can be established subjectively (e.g., based on roadway functional class) or through clustering techniques, although no particular example for doing so is given in the TMG. Shorter duration AVC counts are to cover, at a minimum, 48 consecutive hours, with a recommended monitoring cycle of 6 years. It is suggested that an improvement of between 3 and 5 percent in the accuracy of predicting annual average traffic volumes can be achieved by increasing the duration of classification counts from 24 to 48 h.(13) Low-volume roads exhibited an even higher increase in accuracy because of the higher variation in daily traffic counts.(10) The only exception to the 48-h data collection recommendation is made for urban areas, where traffic congestion imposes variable vehicle speeds. In such situations, it is allowable to collect vehicle classification data over shorter periods of time (e.g., 15 minutes (min)) during which traffic is detected to be moving at a constant speed. The AADTT for vehicle class c (AADTTc) is computed using equation 7, an expression similar to the one for AADT in equation 4. (7)
Where:
Consequently, adjustment factors are developed from continuously operating AVC sites for a particular vehicle class c, DOW i, and month j to AADTT for that vehicle class at location l. They are extensions of equation 6, which by dropping the subscript l for the sake of simplicity, is expressed as equation 8. (8)
Where:
The 2001 TMG(3) gives a slightly different expression, shown in equation 9, for the difference interval d between the true and the estimated AADT and the one used by Ritchie and Hallenbeck.(8) (9)
Where:
The reason for using the Student's t-distribution instead of the normal distribution is that the coefficient of variation in the daily traffic volume population is not really known from the relatively small number of days sampled. The 2001 TMG defines truck load data collection as the means of obtaining the distribution of axle loads by axle configuration and vehicle class for selected roadway groups.(3) This information can be obtained only with WIM systems. Establishing roadway groups with comparable axle-load distribution patterns is essential in maximizing the benefit of the limited number of WIM sites typically available in a jurisdiction. These roadway groups need not be identical to the roadway groups identified with reference to the vehicle classification data obtained from AVC sites. They can be established subjectively (e.g., based on roadway functional class and predominant commodity being carried) or through clustering techniques, although no particular example for doing so is given in the TMG. In establishing the number of WIM sites n required per roadway group, the expression in equation 10 is used. (10)
Where:
Based on this approach and by specifying values of D for GVW and ESAL for class 9 vehicles of 0.19 and 0.13, respectively, a minimum required number of six WIM sites per roadway group is estimated (at 95 percent confidence). It is emphasized that it is more important to have accurate rather than continuous WIM data, although it is preferable to have at least one of the six WIM sites in each roadway group operating continuously. This allows establishment of daily, weekly, and seasonal patterns in the traffic-load data for the particular roadway group. Where continuous operation is not possible, WIM systems should operate for at least a period of 7 continuous days to capture daily variations. NCHRP 1-37A is the main study for the development of a new pavement design guide. (See references 1, 5, 6, and 7.) The mechanistic pavement damage computations in the NCHRP 1-37A design guide require traffic-load spectra, defined as the number of axle passes by load level and axle configuration. In practice, this axle-load spectra information is synthesized by combining data from WIM, AVC, and ATR systems, including either the specific pavement site or other regional/representative traffic data collection sites. Table 4 (of this report) outlines the actual combination of the technology/data used in establishing the load spectra defines four levels of traffic input, as described in Appendix AA in the final report.(1)
It should be noted that the NCHRP 1-37A design guide makes no explicit recommendations on the length of data coverage for these data sets that would produce "reliable" estimates of the required input elements. It should also be noted that these traffic input levels are not rationally related to the input levels identified by the NCHRP 1-37A design guide for other groups of input (e.g., layer properties and environmental data). A more detailed description of the traffic input levels and the technology required for obtaining them is given in table 5.
The axle-load spectra information in the NCHRP 1-37A design guide is synthesized from input arranged in four main modules:
The NCHRP 1-37A design guide considers two types of portland cement concrete (PCC) pavement structures: jointed plain concrete pavement (JPCP) and continuously reinforced concrete pavement (CRCP). JPCP can be either doweled or nondoweled. The following distress mechanisms are considered:
Cracking-related damage is accumulated for both flexible and rigid pavements using Miner's hypothesis. This consists of summing the damage ratios calculated by dividing the actual number of strain cycles by the number of cycles that would cause fatigue failure at this strain level. (11)
Where:
Plastic deformation of flexible pavements and faulting damage of rigid pavements are simply additive. More information on the actual damage functions used for each distress mechanism is given in the final report for the NCHRP 1-37A design guide.(1) NCHRP study 1-39(4) developed a methodology for processing the output of a combination of AVC and WIM systems in a jurisdiction to synthesize the axle-load spectra input to the NCHRP 1-37A design guide for a particular pavement design site.(4) This methodology relies on factoring the available traffic data at that site using the temporal axle-load and vehicle classification distribution patterns from similar sites in the jurisdiction (e.g., State) as prescribed by the 2001 TMG.(3) The type of technology (AVC and WIM) and the length of coverage involved at these traffic data collection sites define the level of traffic input. This methodology is implemented in a software package called TrafLoad. The input of TrafLoad is in terms of the standardized output of AVC and WIM systems, as the hourly summary C-records or 4-cards and the individual vehicle W-records or 7-cards, respectively. The format of the standard cards is given in Appendix A. These data are assumed to have passed independent QC tests before inputting into TrafLoad. In addition, the user needs to input the following information:
The seasonal load spectra is used in factoring incomplete sets of load spectra, as explained later. It should be noted that some of this input, especially the site grouping and the seasonal load spectra computations, may require considerable preprocessing of the available WIM and AVC data before running TrafLoad. TrafLoad distinguishes several levels of traffic input, depending on the load and classification data available at a particular pavement design site/lane. In terms of WIM data availability, there are three pavement design levels:
It should be noted that since levels 2 and 3 lack site-specific WIM data, their assignment to one of the TWRGs is, by necessity, subjective. For complete year-long level 1 WIM data, TrafLoad produces all of the necessary input to the NCHRP 1-37A design guide. For incomplete level 1 WIM data, TrafLoad uses DOW and monthly factor ratios based on complete level 1 WIM sites belonging to the same TWRG. This is done in terms of the pavement damage affected by month and DOW as indexed by the average ESALs per vehicle (AEPV). As shown in equation 12, the daily adjustment ratio (DAR) for a particular DOW d is computed as the average over the number of months available m of the ratio of the AEPV for that missing DOW divided by the monthly AEPV: (12)
Where:
These ratios allow estimation of the number of vehicles by class for missing DOWs, accounting for the relative pavement damage affected in these DOWs. The monthly adjustment ratios (MARs) for a missing month m' is computed from the available months m using equation 13. (13)
Where:
This allows estimation of the number of vehicles for missing months, accounting for the relative pavement damage affected in these months. Finally, load spectra adjustment ratios are computed by load range using equation 14. (14)
Where:
In terms of AVC data availability, TrafLoad distinguishes the following levels:
TrafLoad processes the AVC data from level 1A sites to establish monthly, daily, and hourly trends in vehicle classification counts. This is done in the following sequence:
This information serves two functions: (1) It contributes input to the NCHRP 1-37A design guide for analyzing the particular pavement site, and (2) it provides traffic distribution trends for factoring data from similar sites with lesser AVC information (e.g., AVC sites 1B, 2, and 3). Factoring in TrafLoad is carried out by dividing the short-term count by a traffic ratio. This is a departure from the standard practice that involves multiplying the short-term count by a traffic factor as suggested by AASHTO and the 2001 TMG (i.e., table 3 and equations 6 and 10). The difference between these two apparently equivalent factoring approaches arises when averaging factors versus averaging ratios from a group of sites. The rationale for selecting ratios is that the target value (e.g., AADTT) is in the denominator, and therefore, averaging ratios from a group of AVC sites with the same AADTT would yield the intuitive value of 1.00.(4) As explained next, this study follows the NCHRP 1-37A design guide approach in identifying four traffic data collection input levels by a combination of the traffic data collection technologies involved for a particular site (WIM, AVC, or ATR). It identifies a number of traffic data collection scenarios by extending these four levels identified in table 4 by specifying the length of the site-specific data coverage. Furthermore, this study uses clustering techniques for identifying regional vehicle classification groups and regional axle-load distribution groups. These yield the second and fifth traffic input components to the NCHRP 1-37A design guide, which are in frequency distribution format, as described in table 6; therefore, it is not necessary to establish regional traffic data sets in the conventional TRWG sense, nor is it necessary to use the rather outmoded ESAL concept for doing so.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||