U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-06-121 Date: November 2006 |
This section describes the overall procedure for developing regression models for each of the performance measures considered in the study. The intent of the process was to generate a model with the best prediction capability while ensuring assumptions inherent in the process were not violated. Statistical analysis was performed using SAS® software, version 9.1.3.(14)
All explanatory variables discussed in previous sections of this report were included in the initial regression analysis. These variables were both continuous (i.e., FI) and categorical (i.e., BASE) factors. Table 14 provides a summary of all variables considered in the study as well as details on the format of each parameter.
| Explanatory Variable | Parameter Type |
|---|---|
| Pavement Structure | Categorical |
| Freezing Index (FI) | Continuous |
| Freeze-Thaw Cycles (FTC) | Continuous |
| Cooling Index (CI) | Continuous |
| Annual Precipitation (PRECIP) | Continuous |
| Pavement Age (AGE) | Continuous |
| Subgrade Type (SG) | Categorical |
| Base Type (BASE) | Categorical |
| Asphalt Cement Concrete Thickness (ACTHICK) | Continuous |
| Slab Thickness (D) | Continuous |
| Traffic Loading/Structural Capacity Ration (LESN or LEDT) | Continuous |
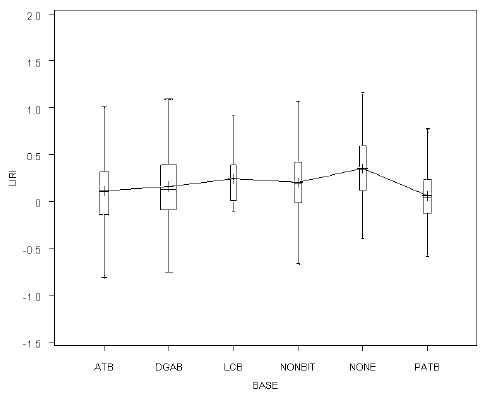
An initial investigation was performed on each of the predictor variables to gain an understanding of the range present in the dataset and the nature of the parameters to be used in the regression modeling. Graphical techniques and descriptive statistical measures were used for this evaluation. These visual techniques allowed for problems with calculations in the dataset or possible outliers to be identified. As an example, a box plot diagram is provided in figure 3, and table 15 presents a sample set of statistical parameters evaluated.
Box plots provide an excellent visual summary of many important aspects of a distribution.(15) The box plot is based on a 5-number summary that includes the median, quartiles, and extreme values. The box stretches from the lower hinge (Q1: 1st quartile) to the upper hinge (Q3: 3rd quartile) and therefore contains the middle half of the scores in the distribution. The median is shown as a line across the box. A quarter of the distribution is between this line and the top of the box and one quarter of the distribution is between this line and the bottom of the box. The plus (+) symbol in box plot represents the mean of the response within that group. The distance between Q3-Q1 is known as interquartile range (IQR). This measure is very useful in detecting outliers in the data. Any observation falling outside Q3+1.5IQR or Q1–1.5IQR could be flagged as potential outlier. Box plots can be useful in detecting right and left skewness as well.
Figure 3. Graph. Sample box plot.
| Variable | N | Mean | Std Dev | Sum | Minimum | Maximum | Label |
|---|---|---|---|---|---|---|---|
| ESAL | 1991 | 209757.0 | 200366.0 | 417627102 | 1.10000 | 1484889 | ESAL |
| SN | 1991 | 5.39970.0 | 1.92871 | 10751 | 0.60000 | 12.20000 | SN |
| ACTHICK | 1991 | 6.33305.0 | 2.83518 | 12609 | 1.00000 | 22.80000 | ACTHICK |
| ELEV | 1991 | 1384.0 | 1569.0 | 2755713 | 8.00000 | 7400 | ELEV |
| LAT | 1991 | 39.50387 | 6.86929 | 78652 | 18.44200 | 64.94800 | LAT |
| LONG | 1991 | 93.88745 | 18.13777 | 186930 | 52.86900 | 156.67000 | LONG |
| FTC | 1991 | 85.63034 | 40.13912 | 170490 | 0 | 192.00000 | FTC |
| FI | 1991 | 360.47850 | 408.44595 | 717713 | 0 | 2584 | FI |
| CI | 1991 | 644.74681 | 523.55940 | 1283691 | 0.10000 | 2506 | CI |
| PRECIP | 1991 | 909.58970 | 388.44307 | 1810993 | 187.30000 | 2020 | PRECIP |
| RUT_AGE | 1991 | 7.86801 | 6.87675 | 15665 | 0 | 31.80000 | RUT_AGE |
| RUT | 1991 | 5.17353 | 4.13532 | 10301 | 0.50000 | 55.00000 | RUT |
Partial regression effects between the response and continuous predictor variables were evaluated, which provided information regarding the independent contribution of each parameter. Figure 4 shows an example of an augmented partial residual plot.
Figure 4. Scatter Plot. Sample augmented partial residual plot.
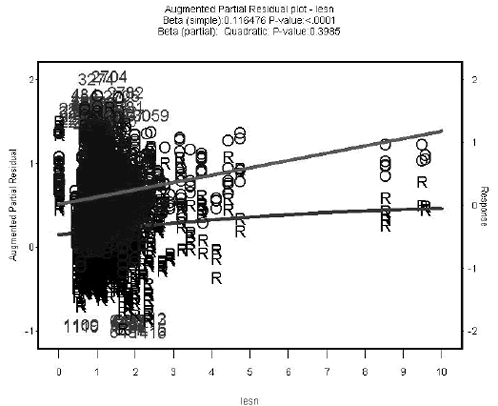
In augmented partial residual plots, both partial linear and quadratic effects of a continuous explanatory variable (equation 6) are plotted against one of the explanatory variables using symbol “R”. The simple regression line (symbol “O”) between the explanatory variable and the response variable is also overlaid in the same plot to show the differences between the simple and the partial effects. This augmented partial residual plot is considered very effective in detecting outliers, nonlinearity, and heteroscedasticity.(15)
| (6) |
Where:
ei=residual
ß1,ß3=coefficients
X1=explanatory variable
While partial regression coefficients present information on the contribution of each predictor variable after controlling for other effects in the model, correlation between variables (i.e., multicollinearity) as well as interacting effects of multiple predictor variables on the performance measure do exist and must be checked. A preliminary analysis of multicollinearity was conducted using an explanatory variable correlation matrix (table 16). In the presence of multicollinearity, the regression parameter estimates become unstable due to a large inflation of the parameter variance. Any two explanatory variables having a significantly larger correlation (>0.9) could be involved in multicollinearity and should be examined by the variance inflation factor (VIF > 10) estimate for each explanatory variable.(15) Significant interaction between any two continuous predictors or between a continuous and categorical predictor variables indicate that the performance measure is influenced by the interacting variables multiplicatively. Omitting significant interaction terms could under- or overestimate the model prediction significantly. Graphical methods were used to examine interaction between continuous and categorical parameters. Interaction plots and the P-values for the interaction terms from the full model were used to check for interaction between two continuous variables and between a continuous and a categorical variable.
Using the knowledge gained through the preliminary review, regression models were developed with all of the explanatory variables and potential interaction terms (identified in the initial review). Resulting P-values were used to determine which variables contributed significantly to the regression model. Generally, parameters with a P-value greater than 0.15 were considered insignificant because there could be more than a 15 percent chance that the regression parameter estimates could be equal to zero, and therefore, should be removed from subsequent regression iterations. In some cases, the independent contribution of an explanatory variable was insignificant, but its interaction effect with other parameters was significant. Both the independent and interacting terms were included in subsequent models when this occurred. Terms that were marginally significant were incorporated in the model only if their contribution improved the prediction capability of the model, which was achieved by iteratiy developing models and evaluating adjusted R-squared, root mean squared error and AIC statistics to select the model that best predicted the observed data. All parameters within a categorical variable were included if one of the parameters was found to be significant. For example, in table 17, all BASE types were included in the model because DGAB is significant. LCB was included even though its contribution was not significant. The entire category must be accounted for in the model if one parameter was found to be significant.
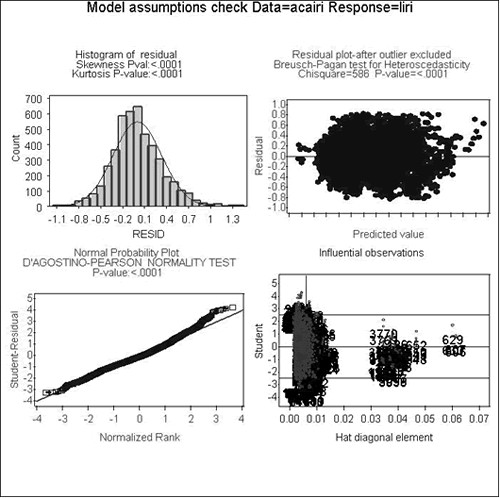
As part of the model development activities, transformations were incorporated to reduce the violation of assumptions inherent in regression models. Figure 5 provides graphical results on the validity of assumptions for the AIRI model before transforming the data. As can be seen from the residual plot (upper right corner of figure 5), the shape of the plot indicates unequal error variance (signified by the diagonal orientation of the bottom boundary of data points). In addition, the normal probability plot (lower left figure) indicates non-normality in the dataset (residual points depart from the straight line). For these reasons, a natural logarithm transformation of the performance measure was performed. The results of the validity check after the transformation can be found in figure 6. As the figure indicates, both the unequal error variance and non-normality have been reduced, thus improving the validity of assumptions in the model.
The final regression models were used to predict mean performance values, and 95 percent confidence intervals were also computed and used in making performance comparisons between the regions. These predictions were made for climatic scenarios of interest in the study.Complete details on this process are discussed in the following section of this report
| ESAL | SN | ACTHICK | ELEV | LAT | LONG | FTC | FI | CI | PRECIP | RUT AGE | RUT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ESAL | 1.00000 | 0.25535 | 0.15887 | -0.09449 | -0.25639 | -0.03808 | -0.16282 | -0.24556 | 0.22145 | 0.13579 | 0.03080 | 0.00151 |
| <.0001 | <.0001 | <.0001 | <.0001 | 0.0894 | <.0001 | <.0001 | <.0001 | <.0001 | 0.1696 | 0.9462 | ||
| SN | 0.25535 | 1.00000 | 0.43217 | 0.05645 | 0.06731 | -0.12238 | 0.22680 | -0.05253 | -0.18038 | -0.10588 | -0.27243 | -0.15508 |
| <.0001 | <.0001 | 0.0118 | 0.0027 | <.0001 | <.0001 | 0.0191 | <.0001 | <.0001 | <.0001 | <.0001 | ||
| ACTHICK | 0.15887 | 0.43217 | 1.00000 | 0.01245 | 0.06886 | -0.09872 | 0.11020 | 0.03918 | -0.14686 | 0.00599 | -0.04717 | -0.02761 |
| <.0001 | <.0001 | 0.5786 | 0.0021 | <.0001 | <.0001 | 0.0805 | <.0001 | 0.7895 | 0.0353 | 0.2181 | ||
| ELEV | -0.09449 | 0.05645 | 0.01245 | 1.00000 | 0.28208 | 0.51202 | 0.76208 | 0.19521 | -0.43518 | -0.78481 | -0.10769 | -0.00238 |
| <.0001 | 0.0118 | 0.5786 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.9154 | ||
| LAT | -0.25639 | 0.06731 | 0.06886 | 0.28208 | 1.00000 | 0.25897 | 0.61287 | 0.76147 | -0.89240 | -0.40206 | -0.08413 | 0.04866 |
| <.0001 | 0.0027 | 0.0021 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.0002 | 0.0299 | ||
| LONG | -0.03808 | -0.12238 | -0.09872 | 0.51202 | 0.25897 | 1.00000 | 0.22746 | 0.17877 | -0.13525 | -0.58561 | -0.01362 | -0.02278 |
| 0.0894 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.5436 | 0.3097 | ||
| FTC | -0.16282 | 0.22680 | 0.11020 | 0.76208 | 0.61287 | 0.22746 | 1.00000 | 0.38152 | -0.78366 | -0.62650 | -0.18159 | 0.02663 |
| <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.2349 | ||
| FI | -0.24556 | -0.05253 | 0.03918 | 0.19521 | 0.76147 | 0.17877 | 0.38152 | 1.00000 | -0.61977 | -0.40330 | 0.05764 | 0.03397 |
| <.0001 | 0.0191 | 0.0805 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.0101 | 0.1297 | ||
| CI | 0.22145 | -0.18038 | -0.14686 | -0.43518 | -0.89240 | -0.13525 | -0.78366 | -0.61977 | 1.00000 | 0.43074 | 0.10822 | -0.02763 |
| <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.2179 | ||
| PRECIP | 0.13579 | -0.10588 | 0.00599 | -0.78481 | -0.40206 | -0.58561 | -0.62650 | -0.40330 | 0.43074 | 1.00000 | 0.13377 | 0.02610 |
| <.0001 | <.0001 | 0.7895 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | <.0001 | 0.2443 | ||
| RUT_AGE | 0.03080 | -0.27243 | -0.04717 | -0.10769 | -0.08413 | -0.01362 | -0.18159 | 0.05764 | 0.10822 | 0.13377 | 1.00000 | 0.43351 |
| 0.1696 | <.0001 | 0.0353 | <.0001 | 0.0002 | 0.5436 | <.0001 | 0.0101 | <.0001 | <.0001 | <.0001 | ||
| RUT | 0.00151 | -0.15508 | -0.02761 | -0.00238 | 0.04866 | -0.02278 | 0.02663 | 0.03397 | -0.02763 | 0.02610 | 0.43351 | 1.00000 |
| 0.9462 | <.0001 | 0.2181 | 0.9154 | 0.0299 | 0.3097 | 0.2349 | 0.1297 | 0.2179 | 0.2443 | <.0001 |
| *The top number in each cell represents correlation; the bottom number denotes the P-value. |
| Regression Parameter | Estimate | Standard | t Value | Pr > |t| |
|---|---|---|---|---|
| Intercept | -1.08 | 0.29 | -3.79 | 0.0002 |
| BASE ATB | 0.45 | 0.15 | 2.89 | 0.0040 |
| BASE DGAB | 0.63 | 0.14 | 4.62 | <.0001 |
| BASE LCB | 0.93 | 0.92 | 1.02 | 0.3101 |
| BASE NONBIT | 0.75 | 0.18 | 4.24 | <.0001 |
| BASE NONE | -0.28 | 0.35 | -0.79 | 0.4284 |
| BASE PATB | 0 | . | . | . |
| SG COARSE | 0.12 | 0.20 | 0.58 | 0.5618 |
| SG FINE | 0.16 | 0.20 | 0.78 | 0.4346 |
| SG | 0 | NA | NA | NA |
| EXP G1 | 0.66 | 0.06 | 10.50 | <.0001 |
| EXP G2 | 0.61 | 0.08 | 7.65 | <.0001 |
| EXP G6 | 0.60 | 0.06 | 10.79 | <.0001 |
| EXP S1 | 0.52 | 0.06 | 8.62 | <.0001 |
| EXP S8 | 0 | NA | NA | NA |
| lesn | 0.77 | 0.13 | 5.84 | <.0001 |
| logrut age | 0.50 | 0.04 | 14.10 | <.0001 |
| CI | 3.4 * 10-4 | 8.2 * 10-5 | 4.11 | <.0001 |
| FI | 1.5 * 10-4 | 1.7 * 10-4 | 0.91 | 0.3649 |
| PRECIP | 1.2 * 10-5 | 6.4 * 10-5 | 0.19 | 0.8475 |
| FTC | 3.5 * 10-3 | 6.9 * 10-4 | 5.02 | <.0001 |
| FI*PRECIP | 3.0 * 10-7 | 1.1 * 10-7 | 2.71 | 0.0068 |
| lesn*logrut_age | -8.4 * 10-2 | 2.6 * 10-2 | -3.25 | 0.0012 |
| logrut_age*CI | -1.4 * 10-4 | 3.2 * 10-5 | -4.44 | <.0001 |
| logrut_age*FI | -1.4 * 10-5 | 3.7 * 10-5 | -0.38 | 0.7063 |
| lesn*BASE ATB | -0.44 | 0.16 | -2.76 | 0.0059 |
| lesn*BASE DGAB | -0.54 | 0.14 | -4.00 | <.0001 |
| lesn*BASE LCB | -0.75 | 1.22 | -0.61 | 0.5416 |
| lesn*BASE NONBIT | -0.66 | 0.15 | -4.28 | <.0001 |
| lesn*BASE NONE | 0.36 | 0.42 | 0.86 | 0.3901 |
| lesn*BASE PATB | 0 | NA | NA | NA |
| FI*BASE ATB | -3.8 * 10-4 | 1.5 * 10-4 | -2.58 | 0.0099 |
| FI*BASE DGAB | -4.2 * 10-4 | 1.3 * 10-4 | -3.20 | 0.0014 |
| FI*BASE LCB | -5.2 * 10-3 | 7.9 * 10-3 | -0.66 | 0.5108 |
| FI*BASE NONBIT | -1.3 * 10-3 | 3.1 * 10-4 | -4.35 | <.0001 |
| FI*BASE NONE | -4.3 * 10-4 | 2.1 * 10-4 | -2.07 | 0.0382 |
| FI*BASE PATB | 0 | NA | NA | NA |
Figure 5. Graphs. Assumption validity check for absolute IRI model (before transformation).
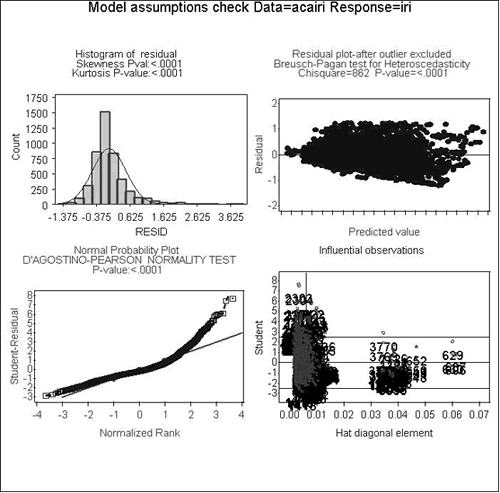
Figure 6. Graphs. Assumption validity check for absolute IRI model (after natural logarithm transformation of the performance measure).