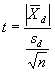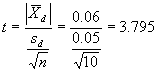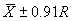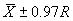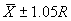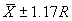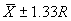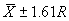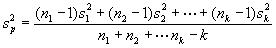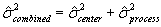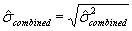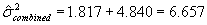U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-02-095 |
Previous | Table of Contents | Next
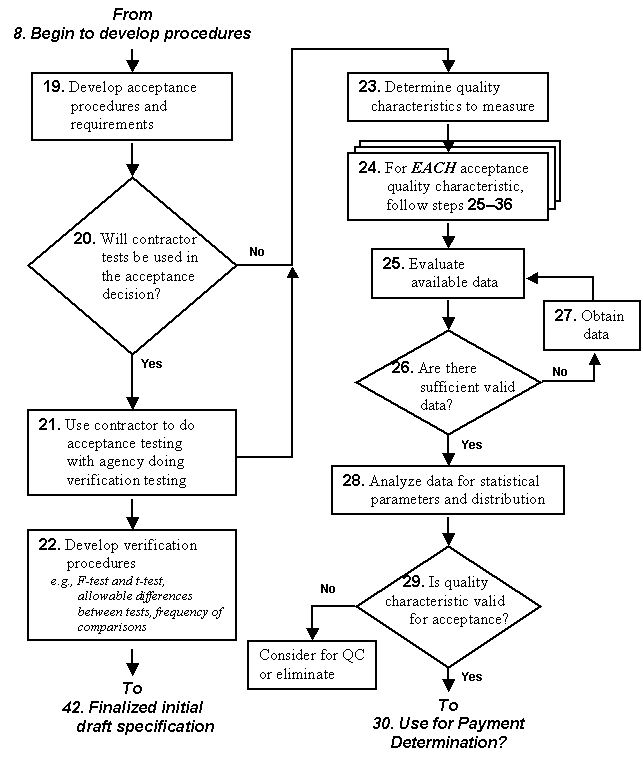
This chapter continues the discussion of Phase II of the specification development process. This chapter is intended to provide "how to use" best practices in the development or modification of the acceptance plan portion of QA specifications. The steps that are involved in this part of the process are identified in the flowchart in figure 7. The numbers in boxes before the titles of the following sections refer to the corresponding box in the flowchart.
There are many important acceptance procedure issues that must be decided upon when developing the acceptance plan and many requirements that can be initiated. As with QC, there is no single prescription that works best in all situations, but there are several that have been effectively used by various agencies.
It is important that the agency determine what it wishes to accomplish with the acceptance plan and its procedures.
The discussions and examples regarding how to analyze data and develop acceptance plans that are presented in this and the following chapters will help an agency to decide how much sampling and testing it believes is economically justified for its particular situation.
As part of the acceptance procedures and requirements, one of the first decisions that must be made is "Who is going to perform the acceptance tests?" The answer to this question will influence subsequent decisions and procedures in the acceptance plan. The agency may decide to do the acceptance testing, may assign the testing to the contractor, may have a combination of agency and contractor acceptance testing, or may require a third party to do the testing.
The decision as to who does the testing usually emanates from the agency's personnel assessment, particularly in days of agency downsizing. However, the lack of personnel availability by the agency should not be the sole reason to decide to use contractor acceptance testing, even though this has often been the case. In fact, agencies have sometimes found no significant decrease in agency personnel resulting from the use of contractor acceptance testing. Also, if an agency adopts contractor acceptance testing solely to reduce the agency's staffing needs, then the agency is less likely to follow all the steps, such as developing appropriate validation procedures and conducting pre-implementation training, necessary to successfully implement the QA specification. Furthermore, contractors should never be assigned the responsibility for acceptance testing without being given sufficient preparation time to assume this task, especially in terms of personnel and facilities.
If the agency does the acceptance testing, "business as usual" will be the predominate theme and the next step is to determine what quality characteristics to measure. If the agency does not do the acceptance testing, then it must decide who will perform that function prior to determining what quality characteristics to measure.
Many agencies are requiring the contractor or a third party to do the acceptance testing. As mentioned, this has often come about, at least partially, because of agency staff reductions. What has often evolved is that the contractor is required to perform both QC and acceptance testing. This is one reason that these two functions can become intermingled if care is not taken to assure their separation. If both functions are assigned to the contractor, it is imperative that the difference between the two functions and the purpose for each is thoroughly explained to both contractor and agency personnel. Additionally, if the contractor is assigned the acceptance function, the contractor's acceptance tests must be verified by the agency. Statistically sound verification procedures must be developed that require a separate verification program. There are several forms of verification procedures and some forms are more efficient than others. To avoid conflicts, it is in the best interest of both parties to make the verification process as effective and efficient as practicable.
If the contractor or a third party acting on behalf of the contractor, such as a consultant, is required to do the acceptance testing, the agency must have a verification procedure to confirm or refute the acceptance test results.
FHWA 23 CFR 637B (6) states the following:
Quality control sampling and testing results may be used as part of the acceptance decision provided that:
The essence of this requirement is a valid and reasonable way to protect taxpayer's interests. An outline of FHWA 23 CFR 637B requirements is shown in appendix E.
The stated use of QC sampling and testing results for acceptance in FHWA 23 CFR 637B (6) does not agree with the philosophical approach used in this manual. That is, that QC and acceptance are separate functions and should not be commingled. The reasons for this are presented and discussed in detail in chapters 3 and 4 of this manual. In this manual, contractor tests that are used in the acceptance decision are referred to as acceptance, rather than QC, tests. QC tests are those used by the contractor for the purpose of process control. While it is true that contractors will definitely relate to their processes the results of the acceptance tests, truly beneficial QC tests are those for which results can be obtained during the process so that adjustments can be made to help ensure that the subsequent acceptance tests will meet the requirements of the acceptance plan.
22.1. Definition of Verification
The TRB glossary (2) defines verification as follows:
As noted in chapter 1, some definitions in FHWA 23 CFR 637B (6) may differ somewhat from those used in this manual. The definitions used here are intended to assure that QC sampling and testing is a separate function from acceptance sampling and testing. However, the need for verification procedures is the same for both sets of definitions. FHWA 23 CFR 637B (6) uses the term "verification sampling and testing" and defines it as "Sampling and testing performed to validate the quality of the product." In this sense, agency verification sampling and testing and agency acceptance sampling and testing have the same underlying function-to validate the quality of the product.
22.2. Independent vs. Split Samples
The TRB glossary (2) contains the following definitions:
FHWA 23 CFR 637B (6) requires that "The verification sampling shall be performed on samples that are taken independently of the quality control samples." Thus, this procedure does not permit the use of split samples. The need for the use of independent samples as opposed to split samples has been questioned by some agencies.
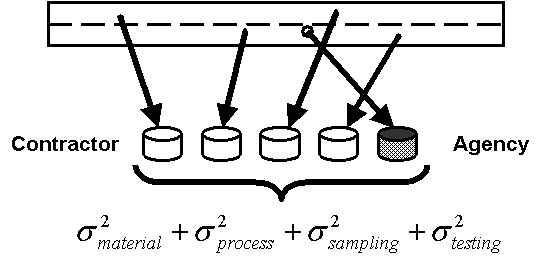
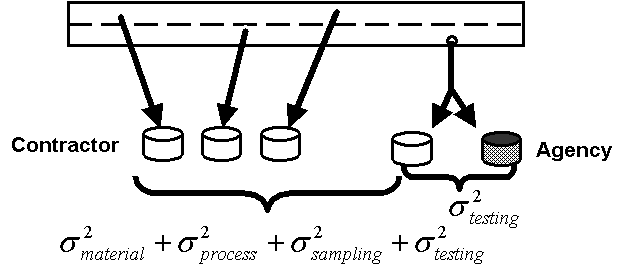
To understand the difference in the information provided by the two sampling procedures, i.e., split vs. independent samples, an understanding of the concept of components of variability is helpful. Variability can come from many different sources. Statisticians sometimes refer to these variabilities as "errors"-sampling error, testing error, etc. These terms mean sampling variability and testing variability, not mistakes. The sources of variability are combined by the use of the basic measure of variability, called the variance, denoted as s 2. The sources of variability are combined by adding the variances (not the standard deviations, denoted as s).
The sources of variability are important when deciding whether to use independent or split samples. The decision depends upon what the agency wants to verify. Independent samples, i.e., those obtained without respect to each other, contain up to four sources of variability: material, process, sampling, and testing method. Split samples contain only testing method variability. These variability components are illustrated in figures 8 and 9.
There has been a considerable amount of confusion between the uses of independent versus split sampling procedures. In an attempt to reduce this confusion, in this manual, the term test method verification refers to the case where split samples are used, while the term process verification refers to the case where independent samples are used.
The statistical implications of these terms extend further than mere definitions. If independent samples are used to verify that two sets of data are statistically similar, then the agency could consider combining the two data sets to make the acceptance decision. Variability issues must be considered when making a decision whether or not to combine the two sets of data. The fact that the data are not shown to be different does not necessarily mean that they are the same. It simply means that they could not be proven to be different given the sample sizes that were involved. Therefore, it is possible that combining the two sets of data could lead to increased variability. On the other hand, the increased number of values in the combined data set might offset a possible increase in variability. In general, it is probably best to use the agency's verification tests simply for verification, and to use only the contractor's acceptance tests if they compare with the agency's tests.
However, if split samples are used to verify two sets of data, these data should not be combined to make the acceptance decision, even when they were determined to be statistically similar. This is because the two split-sample test results represent essentially the same material, and therefore there is little to no additional information provided by using both results. In fact, using both split-sample test results simply represents a double counting of this particular sample location.
22.3. Verification Sampling and Testing Frequencies
There are no universally accepted verification sampling frequencies. However, like any statistical procedure, the ability of the comparison procedure to identify differences between two sets of results depends on several factors. One of these is the number of tests that are being compared-the greater the number of tests, the greater the ability of the procedure to identify statistically valid differences. A minimum agency rate of 10 percent of the testing rate of the contractor or third party has been used as a rule of thumb.
In practice, the verification testing frequency is usually an economic, rather than statistical, decision. The statistics of the issue will generally call for as many, or more, tests as the agency has the resources to perform. A detailed discussion of the effects of verification testing frequency is presented in the technical report for this project. (17)
22.4. Verification Procedures
22.4.1. Hypothesis Testing and Levels of Significance.Before discussing the various procedures that can be used for test method verification or process verification, two concepts must be understood: hypothesis testing and level of significance. When it is necessary to test whether or not it is reasonable to accept an assumption about a set of data, statistical tests, called hypothesis tests, are conducted. Strictly speaking, a statistical test neither proves nor disproves a hypothesis. What it does is prescribe a formal manner in which evidence is to be examined to make a decision regarding whether or not the hypothesis is correct.
To perform a hypothesis test, it is first necessary to define an assumed set of conditions known as the null hypothesis, Ho.Additionally, an alternative hypothesis,Ha, is, as the name implies, an alternative set of conditions that will be assumed to exist if the null hypothesis is rejected. The statistical procedure consists of assuming that the null hypothesis is true, and then examining the data to see if there is sufficient evidence that it should be rejected.Ho cannot actually be proved, only disproved. If the null hypothesis cannot be disproved (or, to be statistically correct, rejected) it should be stated that we "fail to reject," rather than "prove" or "accept," the hypothesis. In practice, some people use "accept" rather than "fail to reject," although this is not exactly statistically correct.
Example
Consider concrete compressive test cylinders as an example. The null hypothesis might be that the average strength of a concrete bridge deck is 35,000 kilopascals (kPa), while the alternative hypothesis might be that the average strength is less than 35,000 kPa. If three tests are performed-and the test results are 30,300, 31,000, and 31,700 kPa-this would seem to be ample evidence in this simple example that the average strength is not 35,000 kPa, so the null hypothesis would be rejected. The alternative hypothesis, that the average strength is less than 35,000 kPa, would therefore be assumed true.
An important technical point to be aware of is that null hypotheses involve equalities (relationships with "=" signs, e.g., average strength = 35,000 kPa, etc.), while alternative hypotheses involve inequalities ("<", ">", or ¹).
Hypothesis tests are conducted at a selected level of significance, a, wherea is the probability of incorrectly rejecting the Ho when it is actually true. The value ofa is typically selected as 0.10, 0.05, or 0.01. If for example, a = 0.01 is used and the null hypothesis is rejected, then there is only 1 chance in 100 that Ho is true and was rejected in error.
22.4.2. Test Method Verification Procedures. The two procedures used most often for test method verification are the D2S limits and the paired t-test.
D2S Limits. This is the simplest procedure that can be used for verification, although it is the least powerful. Because the procedure uses only two test results it cannot detect real differences unless the results are far apart. The value provided by this procedure is contained in many AASHTO and ASTM test procedures. The D2S limit indicates the maximum acceptable difference between two results obtained on test portions of the same material (and thus, applies to only split samples), and is provided for single and multilaboratory situations. It represents the difference between two individual test results that has approximately a 5 percent chance of being exceeded if the tests are actually from the same population.
When this procedure is used for test method verification, a sample is split into two portions and the contractor tests one split-sample portion while the agency tests the other split-sample portion. The difference between the contractor and agency test results is then compared to the D2S limits. If the test difference is less than the D2S limit, the two tests are considered verified. If the test difference exceeds the D2S limit, then the contractor's test result is not verified, and the source of the difference is investigated.
Example
Suppose that an agency wished to use the D2S limits for test method verification of a contractor's asphalt content determination using the ignition method. AASHTO T 308-99, "Determining the Asphalt Binder Content of Hot-Mix Asphalt (HMA) by the Ignition Method," indicates that the D2S limit for two different laboratories is 0.17 percent. So, for a split sample, if the difference between the contractor and agency results is 0.17 percent, or less, the test method would be considered verified. If the difference is greater than 0.17 percent, then the results would be considered different, and an investigation should begin to determine the reason for the difference.
Paired t-test. For the case in which it is desirable to compare more than one pair of split-sample test results, the t-test for paired measurements can be used. This test uses the differences between pairs of tests and determines whether the average difference is statistically different from 0. Thus, it is the difference within pairs, not between pairs, that is being tested. The t-statistic for the t-test for paired measurements is:
where: 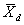 = average of the differences between the split sample test results.
= average of the differences between the split sample test results.
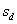 = standard deviation of the differences between the split sample test results.
= standard deviation of the differences between the split sample test results.
n = number of split samples.
The calculated t-value is then compared to the critical value, tcrit, obtained from a table of t-values at a level of a/2 and with n - 1 degrees of freedom. A table of critical t values is presented in appendix F. Computer programs, such as Microsoft® Excel, contain statistical test procedures for the paired t-test. This makes the implementation process straightforward.
Example
Suppose that an agency wished to use the paired t-test for test method verification of a contractor's asphalt content determination using the ignition method. Table 1 shows information on the results of 10 split sample tests that have been conducted.
The t-statistic for the differences in table 1 is
From the table of critical t-values in appendix F, for 9 degrees of freedom (i.e., n - 1, or 10 - 1), the critical value for a level of significance of 0.05 (i.e., a = 0.05) is 2.262. Since 3.795 > 2.262, the agency would conclude that there is a difference between its results and the contractor's results. The reason for this difference should therefore be investigated.
Table 1. Asphalt Content Data for Paired t -test Example
Sample Pair |
Contractor |
Agency Result |
Difference |
|---|---|---|---|
1 |
5.65 |
5.75 |
+0.10 |
2 |
5.45 |
5.48 |
+0.03 |
3 |
5.50 |
5.62 |
+0.12 |
4 |
5.60 |
5.58 |
-0.02 |
5 |
5.53 |
5.60 |
+0.07 |
6 |
5.51 |
5.55 |
+0.04 |
7 |
5.78 |
5.86 |
+0.08 |
8 |
5.40 |
5.49 |
+0.09 |
9 |
5.68 |
5.67 |
-0.01 |
10 |
5.70 |
5.80 |
+0.10 |
Average |
5.58 |
5.64 |
+0.06 |
Standard Deviation |
0.12 |
0.13 |
0.05 |
Recommendation Test Method Verification Procedure. The comparison of a single split sample by using the D2S limits is simple and can be done for each split sample that is obtained. However, since it is based on comparing only single data values, it is not very powerful for identifying differences when they exist. It is recommended that each individual split sample be compared using the D2S limits, but that the paired t-test also be used on the accumulated split-sample results to allow for a comparison with more discerning power. If either of these comparisons indicates a difference, then an investigation to identify the cause of the difference should be initiated. |
A more detailed discussion of verification procedures is presented in the technical report for this project. (17)
22.4.3. Process Verification Procedures. Just as there are statistical tests for verification of split sample test results, there are also tests for verification of independently obtained test results. There are two procedures that appear in the AASHTO Implementation Manual for Quality Assurance. (16) The tests most often used are the F-test and t-test, which are usually used together. However, a procedure that compares a single agency test with 5 to 10 contractor tests is also sometimes used. Both of these are discussed below.
F-test and t-test. This procedure involves two hypothesis tests, where the Ho for each test is that the contractor's tests and the agency's tests are from the same population. In other words, the null hypotheses are that the variabilities of the two data sets are equal, for the F-test, and that the means of the two data sets are equal, for the t-test.
When comparing two data sets, it is important to compare both the means and the variances. A different test is used for each of these comparisons. The F-test provides a method for comparing the variances (standard deviations squared) of the two sets of data. Differences in means are assessed by the t-test. These statistical tests are also commonplace in many computer spreadsheet programs.
The procedures involved with the F-test and t-test may at first seem complicated and involved. The F-test and t-test approach also requires more agency test results before a comparison can be made. These reasons may persuade an agency to seek a simpler approach. However, the F-test and t-test approach is the recommended approach because it is much more statistically-sound and has more power to detect actual differences than the second method that relies on a single agency test for the comparison. Any comparison method that is based on a single test result will not be very effective in detecting differences between data sets.
Some of the complexity of the F-test and t-test comparisons can be eliminated by the use of computer programs. As noted above, many spreadsheet programs have the ability to conduct these tests. In addition, a computer program has been developed specifically for the purpose of making the F-test and t-test comparisons for process verification testing. (18) This program, DATATEST, conducts both the F-test and the appropriate t-test for comparing two sets of data. It can conduct the tests at the 0.01, 0.05, or 0.10 levels of significance.
Examples
Appendix F presents a thorough description, along with examples, of both the hand calculations and computer calculations for the F-test and t-test approach to process verification testing.
Single Agency Test Compared to a Number of Contractor Tests.
In this method, a single agency test is compared with 5 to 10 contractor tests.
The single agency test result must fall within an interval that is defined from
the mean and range of the 5 to 10 contractor test results. The allowable interval
within which the agency test must fall is 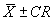 ,
where
,
where 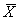 and R are
the mean and range, respectively, of the contractor tests, and C is
a factor that varies with the number of contractor tests. This is not a particularly
efficient approach. This statement, however, can be made for any method that
is based on using a single test. Table 2 indicates the allowable interval based
on the number of contractor tests. These allowable intervals are based on a
level of significance, a, of approximately 0.02.
and R are
the mean and range, respectively, of the contractor tests, and C is
a factor that varies with the number of contractor tests. This is not a particularly
efficient approach. This statement, however, can be made for any method that
is based on using a single test. Table 2 indicates the allowable interval based
on the number of contractor tests. These allowable intervals are based on a
level of significance, a, of approximately 0.02.
Number of Contractor Tests |
Allowable Interval |
|---|---|
10 |
|
9 |
|
8 |
|
7 |
|
6 |
|
5 |
|
ExamplesMore information on this method, including the principles on which it was developed and the magnitude of the difference that is necessary to be identified as significant, are presented in appendix G.
Recommendation While it is in the AASHTO Implementation Manual for Quality Assurance, (16) THIS METHOD SHOULD NOT BE USED. This method was developed to be very simple. It suffers from the fact that only a single agency test is used when making the comparison. Any method that relies on a single data value will not be very powerful at detecting differences. This is due to the high variability that is associated with individual, as compared with mean, values. For example, if the standard deviation for measuring air content in PCC is 0.75 percent, then for a comparison based on five contractor tests, there is only about a 33 percent chance of detecting an actual difference of 2.25 percent between contractor and agency means. The chance only increases to about 57 percent when 10 contractor tests are used. (See appendix G for the development of these values.) |
22.5. Power of the Comparison Procedure (i.e., Hypothesis Test)
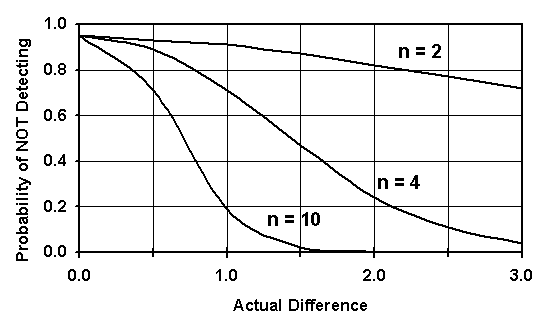
With any statistical test, the larger the number of test results being compared, the greater the chance of making the correct decision. For the procedures described above, there are operating characteristics (OC) curves available to provide guidance regarding the number of tests needed to achieve a certain probability of detecting a given difference when one actually exists. OC curves plot either the probability of not detecting a difference (i.e., accepting the null hypothesis that the populations are equal) or the probability of detecting a difference (i.e., rejecting the null hypothesis that the populations are equal), versus the actual difference between the two populations being compared. Curves that plot the probability of detecting a difference are sometimes call "power curves" because they plot the power of the statistical test procedure to detect a given difference.
Just as there is a risk of incorrectly rejecting the Ho when it is actually true, the Type I, or a, error, there is also a risk of failing to reject the Ho when it is actually false. This is called the Type II or b error. The "power" is the probability of rejecting the Ho when it is actually false, and is equal to 1 - b. Both a and b are important and are used with the OC curves when determining the appropriate sample size to use.
Figure 10 shows a simple OC curve for the probability of not detecting a difference between two populations. The actual difference between the populations is shown on the horizontal axis, while the probability of NOT detecting the difference is shown on the vertical axis. Three OC curves, for sample sizes of n = 2, n = 4, and n =10, are shown in the figure. For each sample size, when the actual difference between populations is zero (i.e., they are equal) there is a 0.95 (or 95 percent) chance of not detecting a difference. That means that there is a 0.05 (or 5 percent) chance that a difference will be detected when the populations are actually equal. This is the Type I, or a, error.
If we are interested in the ability of the statistical test to identify an actual difference of two units, then figure 10 can be used to identify the Type II, or b, error for this situation. While the Type I, or a, error was the same for each sample size, the Type II, or b, error decreases as the sample size increases. For example, in figure 10, the probability of not detecting a difference of 2 units (depicted on the horizontal axis) is about 0.81 for n = 2, about 0.23 for n = 4, and essentially 0.0 for n = 10.
The frequency of comparison is another decision that must be made. There is no universally accepted frequency. The decision sometimes is related to the outcome of the comparison. For example, the verification may be based on one comparison per lot as long as the contractor's test results are verified. However, the frequency may be increased when the results indicate a statistical difference. When a statistical difference is found, it is important to investigate the difference, find the reason for the difference, and correct the problem if one exists.
Examples
The OC curves associated with the test method verification methods and the process verification methods discussed above are presented and explained in appendix G. A number of examples are also included in this appendix. An even more detailed discussion of the OC curves is available in the technical report for this project. (17)
The measurement of performance-related quality characteristics, i.e., those that relate to in-service performance, is preferred in a QA acceptance plan because they provide an indication that the properties being measured are meaningful. If payment adjustments are made based on the test results for these quality characteristics, these performance-related results can be related to quality through some modeling process. This makes the payment adjustment process rational, and not arbitrary. It is also important to select quality characteristics that can be measured by well-established and reliable test methods. This improves credibility in the selection of the quality characteristic.
Occasions arise in which performance-related quality characteristics either do not exist or require tests that are so sophisticated that they do not have the desirable attribute of providing sufficiently quick results for acceptance testing. For these occasions, surrogate quality characteristics may be chosen in place of a performance-related quality characteristic, but only when absolutely necessary. A surrogate quality characteristic is defined here as one that is measured in place of another quality characteristic or to represent one for which a convenient test does not exist.
An example of the possible use of a surrogate quality characteristic might be for fatigue properties of HMAC in which repeated-load bending beam tests provide a desirable measure of fatigue life. However, bending beam tests are time consuming to run and thus are not considered practical for acceptance purposes. Therefore, the indirect tensile strength might be considered as a surrogate quality characteristic for the quality characteristic fatigue life.
Several decisions must be made concerning each acceptance quality characteristic. These decisions include such items as establishing acceptance and/or specification limits, defining acceptable and rejectable quality levels, determining sample size, lot size, sample location, etc. Specific knowledge of each quality characteristic is necessary to make these decisions.
Just as for the QC plan, the sampling and testing procedures for acceptance must be established as well as the specification and/or acceptance limits. To establish these, available data must be analyzed. From where can these data be obtained? Care must be taken when using historical data when developing new acceptance procedures. Historical data may not always be unbiased. In fact, historical data may frequently be biased.
To be valid, the historical data must have been obtained using a random sampling procedure. That is, the sampling locations should have been selected at random, and not systematically or by the judgment of the inspector. When judgment is used for sample selection, bias can be introduced because there may be a tendency to select a sample location where the material looks questionable in an effort to ensure that "bad" material is not incorporated into the project. On the other hand, there could be a tendency to select a sample location where the material looks particularly good in an effort to ensure that the material is accepted. Either of these will provide a biased estimate of the actual properties associated with past construction.
Another potential problem with historical data is the past process of selecting and testing a second sample when the first sample failed to meet the specification requirements. If the second sample met the specifications, and the first sample was therefore disregarded and its value not recorded, then the historical data will tend to underestimate the actual variability associated with the process being measured. The validity of historical data must be scrutinized thoroughly before deciding to use it as the basis for developing new acceptance procedures.
Since the specification and/or acceptance limits will be generic, i.e., agency-wide, the data must not only have been obtained in a manner consistent with their use in the specification, but they must also be broad-based. That means they must have come from production/construction that represents different geographical areas of the State, different contractors with different operations, and projects of different sizes, to mention just some of the considerations. The data must have been obtained by a random sampling procedure and have been sampled and tested in the same manner with the same type equipment as will be required in the new acceptance plan.
There are two questions to be answered. First, are the available data valid? For example, have they been obtained in a random, unbiased manner with all results reported? The next question is have the data been obtained from a sufficient number of different contractors and different size projects to provide a description of the quality characteristic of concern? Are there sufficient data to make the necessary decisions, such as estimating statistical parameters and determining an appropriate probability distribution that will form the basis of the acceptance procedure? If the answer is no, the needed data must be obtained. If the answer is yes, the next step is to analyze the data.
There is not a single answer to what constitutes a sufficient amount of data. What constitutes sufficient data may vary from agency to agency. Data should be from the operations of a number of different contractors, and should cover all of the districts or geographic regions of the State. The data should not be just from operations considered to be superior, but should cover a range of operations from the best to those that are considered to be just acceptable. The specification limits that will be established from these data should not be based on just the best operations, but should be a compromise such that they can be achieved by those operations that the agency deems to have been providing acceptable material. It is likely that data from at least 10, and preferably up to 20, projects will be needed for analysis.
What happens when the data are not sufficient to make the decision on statistical parameters, etc.? From where can these additional data be obtained?
There are several potential sources for the data. The literature review that was undertaken earlier is one potential source for additional data. However, there is often a concern as to how applicable data from other places are to the location for which the acceptance plan is being developed. It is important to ascertain that the data from other sources are applicable since contract payment may be determined from the outcome of the data analysis. Another data source offers a solution to the problem of applicability. This involves gathering new data from ongoing projects on an agency-wide basis. The advantage of this approach is that the data may be viewed as more appropriate than those from a literature review. The disadvantage is that it will be more time consuming to collect data in this manner. If new data must be collected to perform the evaluation, the specification development schedule should then be reexamined to determine whether or not it should be modified and/or extended.
Once there are sufficient data, they must be analyzed to determine the appropriate parameters and distributions to use when developing the acceptance procedures. The analyses should determine the appropriate probability distributions to use to represent the material or process. The analysis should also develop estimates for population parameters-mean, standard deviation, variance, and possibly bias, skewness, and kurtosis-on a project-by-project basis. "Typical" values, particularly for process standard deviation, should also be developed. All of this information may be useful in establishing specification limits and defining quality levels. The use of computerized statistical programs, which typically include histograms and normal probability plots as well as calculation of statistical measures, is recommended.
28.1. Determine Appropriate Probability Distribution for the Data
Attribute acceptance plans do not require that the population from which the data are obtained be from a normal distribution, whereas the use of a variables acceptance plan usually requires that the data be from an approximately normal distribution. Ascertaining that this assumption is correct is important. Visual observation of data histograms, plotting data on normal probability paper, examining skewness and kurtosis values, and statistical goodness-of-fit (GOF) tests, such as the Chi Square and Kolmogorov-Smirnov tests, are some methods available to check the normality assumption.
Although most construction materials cases have been shown to be approximately normal, there are procedures available to assess skewed distributions when they are known to occur. Two ways of addressing skewness are:
ExamplesThe reader is referred to appendix H for a description and examples of some simple methods for assessing the normality of a set of data. More statistically rigorous goodness-of-fit tests are not discussed herein, but their procedures are available in numerous statistical texts.
28.2. Determine Appropriate Process Variability
The first question that must be answered is "What variability will be used for the typical variability on which to base the acceptance requirements?" There are several issues that must be addressed when answering this question, and they are discussed in the following sections.
28.2.1. Which "Project" Variability Is Appropriate? The first, and perhaps most important, issue is to develop a value for project variability that is consistent with the way in which a lot will be defined under the new QA acceptance plan.
Combined "Project" Standard Deviation. It is generally appropriate to combine all test results from a given past project, and to calculate an overall standard deviation value for the combined data, ONLY if in the future the entire project will be used as a single lot for payment determination. Such a decision to use the entire project as the lot, however, assumes that the results from all of the various paving days on the project can be combined to form a single normal population. This may not always be a good assumption in light of the fact that weather changes and process adjustments are frequent occurrences over the life of a typical paving project. In the past, some agencies have calculated combined overall project standard deviation values and then used these to establish specification limits where there is lot-by-lot, rather than total project, acceptance. This is NOT correct, and should not be done.
Typical "Within-Lot" Standard Deviation for a Project. If the new acceptance plan will be based on lot-by-lot acceptance, then the variability that is used to establish the specification limits must be that which is appropriate for a typical lot. In such a case, it is NOT appropriate to combine all test results from a project and then to calculate a standard deviation for these combined data. The individual standard deviation values for each lot must be calculated and then these lot standard deviations are pooled to get a typical "within-lot" standard deviation for the process.
How the individual lot standard deviation values are averaged or combined depends upon the number of test results there are for each lot. From a statistical standpoint, the number of test values for each lot is known as the sample size, or n. In this case, sample size refers not to the quantity of material that comprises the individual test portions, but to the number of test results on which the lot information is based. That is, if there are four tests from each lot, then the sample size is n = 4.
Sample Standard Deviation. In statistical terms, the sample standard deviation is referred to as s. The individual lot (or sample in statistical terms) standard deviations cannot directly be used to estimate the within-lot process (or population in statistical terms) standard deviation. This is true because the sample standard deviation is a biased estimator for the population standard deviation. Therefore, if the individual sample standard deviations are used to estimate a population standard deviation, then a correction factor MUST be applied to adjust for the bias in the estimate. This correction factor is applied to the arithmetic average (or mean in statistical terms) of a number of individual lot standard deviation values, and the sample size should be the same for each of the individual lots. Because of these limitations, it is rarely appropriate to estimate the typical within-lot project standard deviation based on the individual lot standard deviations.
Warning! It is NOT correct to average individual lot standard deviation values to get a typical project standard deviation. The sample standard deviation is a biased estimator of the population standard deviation. It is acceptable to use the lot standard deviations to estimate the population standard deviation ONLY if the sample size is the same for each lot and if the appropriate correction factor is applied. The following method that uses the sample variances is the correct and recommended method. |
Sample Variances. The preferred method for estimating the within-lot process standard deviation is by using the lot variances rather than standard deviations. This is true because the sample variance is an unbiased estimator of the population variance. Therefore, the individual lot variances can be "pooled" to provide an unbiased estimate for the within-lot process variance. The square root of the pooled project variance will then be an unbiased estimate for the within-lot process standard deviation. The pooled variance is a weighted average based on the sample sizes associated with the individual lot variances. In statistical terms, if we assume that our individual lot values are from the same population or from different populations having equal variances, then the individual lot variances can be pooled to give an estimate for the within-lot process variance. The formula for this estimate, if there are k individual lots,is
where: s 2 p = pooled estimate for the within-lot process variance.
s 2i = variance for lot i, where i = 1, 2, _k.
ni = number of values for lot i.
k = number of lots in the project.
The pooled standard deviation is then simply the square root of the pooled variance. Although this equation assumes sampling from populations having equal variances, it is generally believed to be adequate for this application when developing acceptance plans.
ExampleThe test results from a past project are shown in table 3.
Table 3 indicates that when all 40 of the individual test results are combined into one data set, the variability, as indicated by the standard deviation, is 0.69. However, when the standard deviations of the 10 individual lots are pooled using equation 5-3, the "within-lot" process standard deviation is 0.61.
If an agency decides that it will base acceptance on a project-sized lot, then the correct standard deviation to represent this project is 0.69, which is based on a sample size of n = 40 tests in the project. However, if the agency decides that acceptance will be on an individual lot basis, then the approximate standard deviation to represent a typical lot on this project is 0.61, with a sample size per lot of n = 4.
Lot |
Test Results |
n |
Lot |
||
|---|---|---|---|---|---|
Mean |
Std Dev |
Variance |
|||
1 |
4.6, 5.3, 5.5, 4.8 |
4 |
5.05 |
0.420 |
0.176 |
2 |
6.0, 5.7, 5.1 |
3 |
5.60 |
0.458 |
0.210 |
3 |
5.2, 3.7, 4.2, 5.0 |
4 |
4.53 |
0.699 |
0.487 |
4 |
6.3, 6.1, 4.9, 6.0, 5.3 |
5 |
5.72 |
0.593 |
0.352 |
5 |
5.2, 5.0, 3.6 |
3 |
4.60 |
0.872 |
0.760 |
6 |
5.8, 4.9, 4.5, 5.5 |
4 |
5.18 |
0.585 |
0.342 |
7 |
4.9, 4.7, 3.5, 4.6 |
4 |
4.43 |
0.629 |
0.396 |
8 |
5.9, 5.6, 4.2, 5.5, 4.7 |
5 |
5.18 |
0.705 |
0.497 |
9 |
5.9, 5.7, 4.4, 5.6 |
4 |
5.40 |
0.678 |
0.460 |
10 |
4.4, 4.6, 5.0, 4.8 |
4 |
4.70 |
0.258 |
0.067 |
Individual Tests |
40 |
5.1 |
0.69 |
||
Pooled for 10 Lots |
10 |
0.61 |
0.371 |
||
28.2.2. Selecting a "Typical" Process Variability. After determining typical within-lot process variabilities for various projects, it can then be determined if the data from contractors are reasonably consistent, or whether some have appreciably lower or higher variabilities than others, whether some meet the specification requirements more often than others, etc. This is important when trying to select a "typical" within-lot variability for the overall process (or, process variability). For instance, the typical process variability should not be set for the most or least consistent contractor.
As noted above, the data must come from a number of different projects as well as different contractors. The number of projects to consider will vary depending upon the number of contractors that work in the State, the number of different geological regions in the State, and how much the process variabilities differ among projects and contractors.
Once the project variability data are available, a decision must be made regarding what variability to use as the "typical" process variability. This typical variability will then be used to establish specification limits. There is no single "correct" way to decide upon the typical variability to use. An example may help to clarify some of the factors involved in the decision.
ExampleSuppose that a highway agency has collected data from 10 past projects that it considered acceptable, and determined the results shown in table 4.
The agency could decide to select 1.65 as the "typical" process standard deviation value (measure of process variability) since this value is "capable" of being achieved. On the other hand, the agency could select 3.20 since this value was obtained on a project that the agency had apparently considered acceptable. It is probably not appropriate to select either the best (smallest) variability or the worst (largest) variability as the "typical" variability. An agency cannot reduce variability by simply specifying it, particularly if it has been shown that contractors, in general, have not been able to consistently meet that variability value. It is probably also not a good practice to base acceptance plan decisions on the worst contractor results.
Therefore, the agency would probably wish to select the typical process variability value based on consideration of all of the past project data rather than just a single best or worst project. The agency might order the standard deviation values from smallest to largest. This yields: 1.65, 2.03, 2.05, 2.12, 2.20, 2.35, 2.51, 2.71, 2.84, 3.20. A subjective decision could then yield several possible "typical" values. For instance, 2.51 might be selected since 7 of 10 projects had this value or less, and because there was a fairly large gap to the next higher value (2.71). Similarly, 2.84 might be selected because of the very large gap between this value and the largest value of 3.20. Other subjective choices are possible.
There is no single "correct" way to decide on the typical value for process variability. The agency should consider various options and select the method with which it is most comfortable for the given project data.
|
Project |
Project Standard Deviation |
Project |
Project Standard Deviation |
|---|---|---|---|
|
A | 1.65 |
F |
2.51 |
|
B | 2.05 |
G |
3.20 |
|
C | 2.84 |
H |
2.20 |
|
D | 2.12 |
I |
2.71 |
|
E | 2.35 |
J |
2.03 |
28.3. Consider Target Value Miss
The typical standard deviation value that is selected serves as a measure of variability within the process, i.e., the "within-process" variability, for a typical contractor on a typical project. This standard deviation will be used to help decide upon specification limits for the acceptance plan. Another factor that needs to be considered in addition to this within-process variability is the capability of contractors to center their processes on the target value. This may be an even more difficult task than deciding on a typical within-process standard deviation.
28.3.1. Combined Typical Standard Deviation. Many possible quality characteristics have target values about which two-sided specification limits will be established. As shown later in this manual, the identified typical process standard deviation can be used to establish these specification limits. The agency, however, must decide whether or not a typical contractor can be expected to always be able to center its process exactly on the target value. If the agency believes this to be possible, then the typical process standard deviation that was developed from the analyses in previous sections is the correct one to use when setting the specification limits. If, on the other hand, the agency believes that a typical contractor's process mean may vary somewhat about the target value, then it will be necessary to consider this fact when developing specification limits.
It is not reasonable to assume that a contractor can always set its process mean precisely on the target value. Differences in materials, weather conditions, conditions of the existing pavement, and other factors may lead to a contractor's process mean occasionally missing the target value in spite the contractor's best efforts to hit it. If current technology does not allow for the process mean to always be "on target," then the agency needs to consider this when establishing specification limits. Since this target miss will add additional variability to the within-process variability, this will lead to wider specification limits than those established based strictly on the typical process standard deviation.
What is being discussed here is not the case where a contractor, for whatever reason, chooses to intentionally center its process at some point other than the target value. If a contractor chooses to do this, then the contractor must bear any potential acceptance risks associated with its decision. On the other hand, failure to consider that current technology may not be adequate to allow the contractor to always hit the target with all of its processes places an unfair risk on the contractor.
The proper way to address the issue of "target miss," is to determine how variable the actual process means are about the target value. This variability regarding where the process will be centered, call it "process center variability," can then be combined with the previously determined typical within-process variability to obtain the correct standard deviation value for use in establishing specification limits.
The "process center variability" and the "within-process variability" can be combined simply by adding their associated variances, NOT their standard deviations. This assumes that the amount of process variability is independent of where the process is centered, an assumption that seems reasonable, particularly as long as the target miss is not very large. Note that it is NOT correct to add the two standard deviations. The two variances must be added to get a combined variance. The square root of this combined variance is then the correct combined standard deviation value to use. This relationship is shown in the following equations.
where: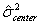 = estimated process center variance.
= estimated process center variance.
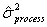 = estimated within-process variance.
= estimated within-process variance.
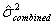 = estimated combined process center and within-process variance.
= estimated combined process center and within-process variance.
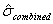 = estimated combined standard deviation.
= estimated combined standard deviation.
The true answer as to how much process center variability exists is extremely difficult to obtain. The decision may require some engineering judgment since an analysis of data is not likely to be able to yield a clear answer to the question.
One reason that it is difficult to answer this "target miss" question from project data is that the agency never knows with certainty where the contractor intended to center its process. A contractor with particularly low variability could, for a number of reasons, choose to center its process at a point other than the target value and still plan to meet the specification requirements based on its low variability. It will also not be possible to determine from project data whether or not the contractor's process mean was constant throughout the project or whether for any of a number of reasons it was changed during the course of the project. Any "target miss" analysis will therefore require some assumptions on the part of the agency. Each individual agency must decide, based on its experience, what assumptions it believes are appropriate.
28.3.2. Assuming a Constant Process Throughout the Project. If the agency developed its typical standard deviation by combining all test results from the project, i.e., it decided to use the total project for the acceptance lot, then the agency has already assumed that the contractor's process remains constant throughout the project. If this assumption is made, then it is possible to use data from a number of projects to estimate the "target miss" variability. As mentioned in the previous discussion for establishing a typical process variability value, it seems unlikely that a contractor's process will be identical throughout the life a large project. This is the reason that an agency would choose to use the within-lot variation to establish the typical process standard deviation.
However, if the agency does assume a constant process throughout a project, then the mean value for all of the lot means on the project will be a good estimate of where the process was centered for the project. The agency could then obtain a large number of project "target misses" and analyze these to determine the variability associated with missing the target value. An example will help to illustrate how this could be done.
ExampleSuppose an agency is willing to assume that a contractor's process remains constant throughout an entire project. The agency could then determine an "average target miss" value for a specific project by subtracting the target value from the average of all of the test results on the project.
Assume that the agency has obtained the following "average target miss" values from 13 past projects:
-0.30, -1.28, +0.24, +1.28, +1.20, +1.73, -2.18, -0.23, +1.10, -1.09, -0.69, -1.69, +1.85.
The mean for these 13 project "target misses" is 0.00. This indicates that, on the average, contractors are probably aiming for the target. The standard deviation for these 13 "target misses" is 1.348, with a corresponding variance of 1.817. These values represent the variability associated with hitting the target value.
Now assume that the agency had previously selected the typical process variability to be represented by a standard deviation of 2.20, with a corresponding variance of 4.84. The combined standard deviation to use for establishing specification limits can then be calculated using equations 6 and 7:
Caution The method described in the above example applies ONLY if the agency has decided to assume that the contractor's process remains constant throughout the entire duration of a project. If it is believed that the contractor's process mean may vary from lot-to-lot within a project, which seems likely, then the above approach is NOT appropriate. |
28.3.3. Assuming Process Not Constant Throughout Project. If the agency does not believe that the contractor's process is constant throughout the life of a project, as would typically be the case when the agency has decided to use lot-by-lot acceptance, then the procedures in the previous example would NOT be appropriate. In this case there is no easy way to determine a typical "target miss" variability since there is no way to know how much of the lot-to-lot variation in sample means is from the natural variation of the sampling process and how much is due to misses, changes, or adjustments in the contractor's target mean during the project. To address this situation, the agency must make some assumptions. Which assumptions are made will depend upon the individual agency and what it believes to be the most reasonable for its State, contractors, and processes.
One possibility might be to calculate a standard deviation based on combining all of the project data into one data set. While this was not recommended above in the discussion on how to establish a process standard deviation to use with lot-by-lot acceptance, this approach will provide a larger standard deviation value that includes the lot-to-lot variation in lot means. A decision to use this approach assumes that any "target miss" variation within the project will be accounted for when all the test results are combined. The various project standard deviations could then be pooled, using their corresponding variances, to arrive at a typical process standard deviation that attempted to include the possible "target miss" variability.
Another possible approach would be for the agency to use some experience, engineering judgment, and knowledge of the process to develop a reasonable estimate for the "target miss" variability. The agency could base its decision on its past experience as well as discussions with contractors in the State. A very simple example shows how an agency might arrive at a value for "target miss" variability.
ExampleSuppose that an agency wishes to determine a "target miss" standard deviation for a particular quality characteristic. Based on the judgment of experienced agency personnel and discussions with contractors, the agency believes that most of the time a contractor can control its process mean to within ±1.5 units of the target mean.
Next, the agency might decide to assume that "most" of the time can be represented by ±2 "target miss" standard deviations. This would correspond to about 95 percent of the time. Under this assumption, the "target miss" standard deviation would be about 1.5 ÷ 2 = 0.75 units. If the agency had previously decided upon a "within-process" standard deviation of 2.75 units, the combined standard deviation for developing specification limits can be calculated using equations 8 and 9.
28.4. Identification and Explanation of Data Anomalies
Anomalies in the data should be identified and, if possible, explained. There may be something in the contractor's operation, the sampling and testing, etc., that leads to the anomaly, and should, therefore, be considered for inclusion or exclusion in the acceptance plan. For example, if data from one project are quite different from the other projects it may be determined that there were special circumstances, such as nighttime paving in cold weather, involved on this project. The agency would then need to decide whether or not it wished to consider this project when establishing the new acceptance plan requirements.
28.5. An Ongoing Process
As seen from the previous sections, there is no single, clear-cut "correct" method to establish the typical standard deviation value to use when setting specification limits. Each of the possible methods requires some assumption or assumptions by the agency. Each individual agency must decide which of these assumptions it believes are most appropriate for its given situation. Whichever method the agency uses to determine the standard deviation that it uses to set specification limits, the agency should not consider the process to be finished. Once the new acceptance plan is implemented, the agency must continue to collect and to monitor data from projects to verify that the assumptions that were made when developing the acceptance plan were appropriate. It is important that the monitoring data be obtained in the same fashion as the original data that were used to establish the initial typical standard deviation value for the process. The agency must then be willing to modify its typical standard deviation value and corresponding specification limits if the additional project data indicate that it is necessary.
As a final check, each quality characteristic that was selected for acceptance purposes should be reconsidered once data have been collected, analyzed, and reviewed by the agency/industry task force. A final decision is then made whether or not to include the tests to measure each quality characteristic in the stipulated acceptance requirements. If the decision is to not measure the quality characteristic for acceptance purposes, then the task force should decide whether the quality characteristic should be considered for possible QC testing, or should be eliminated from further consideration.