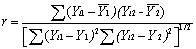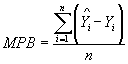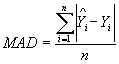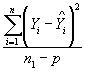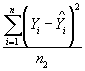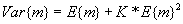U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-03-037
Date: May 2005 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Validation of Accident Models for IntersectionsFHWA Contact: John Doremi, PDF Version (1.61 MB)
PDF files can be viewed with the Acrobat® Reader® 2. VALIDATION OF ACCIDENT MODELSThis chapter presents validation results for the five types of rural intersections. It first provides a description of the overall validation approach. Second, the data sources and issues are discussed. Third, the individual validation activities and their results are presented. Finally, a discussion of these results is provided. 2.1 VALIDATION APPROACH AND PRELIMINARIESSeveral objectives were identified to guide the validation efforts:
To meet these objectives, researchers conducted two aspects of model validation: internal and external model validations. The first aspect of model validation consists of qualitative assessments of statistical models, including examining the collection of variables used to identify missing or irrelevant variables, inspecting the functional form of the models, and assessing the implications of the models regarding an underlying theory of the data generating process-motor vehicle crashes, in this case. External model validation is more quantitative and is focused on various quantitative measures of a statistical model's prediction ability. Three model validation activities comprising both internal and external validation activities were undertaken:
The validation exercises in this chapter focus primarily on external validation-validation concerned with assessing performance of the models when compared to external data. The discussion section mentions internal validation concerns-the internal coherence, structure, theoretical soundness, and plausibility of the models proposed. And more focus is given to internal validation in the recalibration activities documentation, which follows the report on these validation efforts. In these validation activities, all model specifications were validated "as is," that is, no changes to model specifications were considered or assessed. Throughout the report the subjective criteria of alpha ( Several goodness-of-fit (GOF) statistics to assess model fit to validation data were employed. Comparisons between models, however, are generally subjective. In the documentation to follow, the terms "serious," "moderate," and "marginal" denote subjective evaluations of GOF comparisons between models. Serious differences in GOF are suggestive of noteworthy or significant model deficiencies. Moderate differences in GOF suggest cases where models could be improved, but improvements might be difficult to obtain. Marginal differences in GOF are thought to be negligible and are potentially explained by random fluctuations in the observed data. 2.2 DATA SOURCES AND ISSUESThis section presents the data sources used for the validation and some general data issues. The data used came from three sources:
The first validation activity employed the original datasets with the objective of reproducing the original models. In the second validation activity, additional years of accident data (1990 to 1998) from Minnesota were used to validate models I and II over time. The Washington data collected, but not used, for the final development of models I and II, plus accident data for one more year (1996) also were utilized. For models III, IV, and V, additional years of accident data (1996 and 1997) from California and Michigan were used to validate the models over time. For the third validation activity, data from Georgia were assembled during this project and used to further assess the models' ability to predict accidents over space (in a different jurisdiction). The fourth validation activity assessed the "Red Book" accident prediction algorithm, including recommended base models.(3) Models I and II, which were developed using Minnesota data, modeled police reported "intersection" or "intersection-related" accidents which occurred within 76.25 m (250 ft) of the intersection. Models III, IV, and V were each developed using Michigan and California data for two dependent variables. The first used all accidents occurring within 76.25 m (250 ft) of the intersection. The second used only those accidents considered to be "intersection-related" and occurring within 76.25 m (250 ft) of the intersection. Special criteria were needed for the latter case because California data does not include a variable indicating if an accident was "intersection-related." An accident was considered to be intersection related accidents if it was:
Vehicle-bicyclist, head-on, and run-off-the-road crashes may could possibly be classified as intersection related but were not included in the analysis in order to maintain consistency and comparability with previously estimated models from which this research was based.(2) According to discussions with FHWA, for four-leg STOP-controlled intersections, these crashes typically represent about 6 percent of the total crashes occurring within 76.25 m (250 ft) of the intersection. For three-leg STOP-controlled intersections, these crashes typically represent about 13 percent of the total crashed occurring within 76.25 m (250 ft) of the intersection. Table 1. Basic Statistics for the Data Sources
1 Vogt and Bared 1998, (pp. 60-67) 2 Vogt, 1999, (pp. 53-64) 3 MN: Minnesota, WA: Washington, CA: California, MI: Michigan, GA: Georgia. 4 TOTACC: Total number of accidents within 76.25 m (250 ft); TOTACCI: Only those crashes considered intersection-related and within 76.25 m (250 ft); Similar distinction between INJACC and INJACCI The Georgia data specially collected for this validation also do not include a variable coded as "intersection" or "intersection-related" by the police. As such, the above criteria for determining an "intersection-related" accident were used. To use the Georgia data to validate the original models, consistency of accident location definitions had to be resolved. The original models included accidents only within 76.25 m (250 ft) from the intersection center. However, the accident data recorded in Georgia measures the distance of an accident from an intersection within two decimal places of a mile, i.e., within 8.05 m (26.4 ft). The issue was whether or not to include accidents within 0.06 or .08 kilometers (km) (0.04 or 0.05 miles, or 211 or 264 ft). In the end, both the 0.04- and 0.05-mile buffers were used in separate validation efforts, mainly to check the sensitivity of the results to this definition. 2.3 MODEL PERFORMANCE MEASURESSeveral GOF measures were used to assess model performance. It is important to note at the outset that only after an assessment of many GOF criteria is made can the performance of a particular model or set of models be assessed. In addition, a model must be internally plausible, and agree with known theory about crash causation and processes. The GOF measures used were: Pearson's Product Moment Correlation Coefficients Between Observed and Predicted Crash Frequencies Pearson's product moment correlation coefficient, usually denoted by r, is a measure of the linear association between the two variables Y1 and Y2 that have been measured on interval or ratio scales. A different correlation coefficient is needed when one or more variable is ordinal. Pearson's product moment correlation coefficient is given as:
where
A model that predicts observed data perfectly will produce a straight line plot between observed (Y1) and predicted values (Y2), and will result in a correlation coefficient of exactly 1. Conversely, a linear correlation coefficient of 0 suggests a complete lack of a linear association between observed and predicted variables. The expectation during model validation is a high correlation coefficient. A low coefficient suggests that the model is not performing well and that variables influential in the calibration data are not as influential in the validation data. Random sampling error, which is expected, will not reduce the correlation coefficient significantly. Mean Prediction Bias (MPB) The MPB is the sum of predicted accident frequencies minus observed accident frequencies in the validation data set, divided by the number of validation data points. This statistic provides a measure of the magnitude and direction of the average model bias as compared to validation data. The smaller the average prediction bias, the better the model is at predicting observed data. The MPB can be positive or negative, and is given by:
where n = validation data sample size; and
A positive MPB suggests that on average the model overpredicts the observed validation data. Conversely, a negative value suggests systematic underprediction. The magnitude of MPB provides the magnitude of the average bias. Mean Absolute Deviation (MAD) MAD is the sum of the absolute value of predicted validation observations minus observed validation observations, divided by the number of validation observations. It differs from MPB in that positive and negative prediction errors will not cancel each other out. Unlike MPB, MAD can only be positive.
where n = validation data sample size. The MAD gives a measure of the average magnitude of variability of prediction. Smaller values are preferred to larger values. Mean Squared Prediction Error (MSPE) and Mean Squared Error (MSE) MSPE is the sum of squared differences between observed and predicted crash frequencies, divided by sample size. MSPE is typically used to assess error associated with a validation or external data set. MSE is the sum of squared differences between observed and predicted crash frequencies, divided by the sample size minus the number of model parameters. MSE is typically a measure of model error associated with the calibration or estimation data, and so degrees of freedom are lost (p) as a result of producing Yhat, the predicted response.
where n1 = estimation data sample size; and n2 = validation data sample size. A comparison of MSPE and MSE reveals potential overfitting or underfitting of the models to the estimation data. An MSPE that is higher than MSE may indicate that the models may have been overfit to the estimation data, and that some of the observed relationships may have been spurious instead of real. This finding could also indicate that important variables were omitted from the model or the model was misspecified. Finally, data inconsistencies could cause a relatively high value of MSPE. Values of MSPE and MSE that are similar in magnitude indicate that validation data fit the model similar to the estimation data and that deterministic and stochastic components are stable across the comparison being made. Typically this is the desired result. To normalize the GOF measures to compensate for the different numbers of years associated with different data sets, GOF measures were computed on a per year basis. For MPB and MAD per year, MPB and MAD were divided by number of years. However, since MSPE and MSE are the mean values of the squared errors (MPB or MAD were squared and divided by n or n-p), MSPE and MSE were divided by the square of number of years to calculate MSPE and MSE per year, resulting in a fair comparison of predictions based on different numbers of years. Overdispersion Parameter, KThe overdispersion parameter, K, in the negative binomial distribution has been reported in different forms by various researchers. In the model results presented in this report, K is reported from the variance equation expressed as:
where Var{m} = the estimated variance of the mean accident rate; E{m} = the estimated mean accident rate; and K = the estimated overdispersion parameter. Variance overdispersion in a Poisson process can lead to a negative binomial dispersion of errors, particularly when the Poisson means are themselves approximately gamma distributed, or possess gamma heterogeneity. The negative binomial distribution has been shown to adequately describe errors in motor vehicle crash models in many instances. Because the Poisson rate is overdispersed, the estimated variance term is larger than the same under a Poisson process. As overdispersion gets larger, so does the estimated variance, and consequently all of the standard errors of estimates become inflated. As a result, all else being equal, a model with smaller overdispersion (i.e., a smaller value of K) is preferred to a model with larger overdispersion. 2.4 VALIDATION ACTIVITY 1: VALIDATION USING ADDITIONAL YEARS OF ACCIDENT DATAThe acquisition of subsequent years of accident data allowed for the validation of the models across time. For the type I and II models, although data from both Minnesota and Washington were collected, only data from Minnesota were used for the final calibration. Only the models developed using Minnesota data were validated because a report by Vogt and Bared states that "in view of the small size of the Washington State sample ... the non-random and ad hoc character of the Washington intersections, the lesser quality of the collected Washington data ... we take the Minnesota models as fundamental." (p. 123)(1) However, the Washington data were still obtained to further assess the transferability of these models over time and across jurisdictions. The original report performed a similar validation exercise with Washington data but with fewer years of accident data. The validation undertaken for this activity included applying the original models to the new data and assessing various measures of GOF. It also included recalibrating the models using the additional years of data and comparing the parameter estimates with those of the original models. The Type I and II models were originally calibrated on accident data from 1985 to 1989. In the original report, 1990 to 1993 data were used to validate the models in addition to the Washington data. The results for the MAD are given in Table 2. Table 2. Validation Statistics from Original Report1
1 Vogt and Bared, 1998, (p. 131-132) For the new validation of Type I and II models, accident data from 1990 to 1998 were obtained to expand the validation dataset. For the Type III, IV, and V models, the original models were developed with accident data that were collected between 1993 and 1995. Accident data collected between 1996 and 1997 at the same locations were acquired to validate the models.Data Limitations in the Minnesota Data Because site characteristics change over time, the original sites were examined on important variables to determine which ones were no longer suitable for inclusion. Also, any sites where any year of accident data was missing was not included. Of the 327 original four-legged sites, 315 were retained while 367 of the original 389 three-legged sites were retained. The sites that were excluded typically changed from being a rural to a suburban environment, changed in the number of legs, and changed traffic control or had missing years of accident data. Subsequent to the analysis and draft report, it was discovered that the mile log information that identifies the location of an intersection for some sites had changed over the 1990 to 1998 period. Although errors will exist in the accident counts used at these sites, these errors were found to be negligible. For example, for Type I sites, the average number of accidents per site per year in the validation data was 0.25 and 0.11 for total and injury data, respectively. In the corrected data, these averages are 0.26 and 0.11. Therefore, the conclusions drawn from the analysis are not affected and the analysis has not been redone. Data Limitations in the Michigan Data Traffic volumes from 1993 to 1995 were not updated for this validation exercise because AADT information for major and minor roads for 1996 and 1997 were not available. One of the complexities regarding AADT acquisition is outlined in the report published originally by Vogt.(2) In the original data, minor road AADT from 1993 to 1995 was not available for Michigan intersections. Therefore in the report, major AADT plus peak-hour turning movement counts were used to estimate missing years of minor road AADT. Subsequent to the analysis and draft report it was discovered that for type V sites from Michigan, the original researchers manually identified crossroad mileposts for about 40 percent or more of these intersections (State routes) and counted accidents that occurred on the crossroads. At non-State route crossroads, accidents are mileposted to the mainline. However, the Michigan accident data for 1996 and 1997 years obtained did not include the crossroad accidents at intersections with a State route crossroad because the validation team did not have the crossroad milepost information at that time. As a result, the later year crossroad accident numbers at these sites should be systematically lower than expected. 2.4.1 Model IThe summary statistics shown in table 3 indicate that there are similar accident frequencies between the original (1985-89 data for 389 sites) and the additional (1990-98 data for 367 sites) years. Note that the statistics compare 5 years of accident data in the original set to 9 years of accident data for validation over time. The latter years of data exhibit an increased variability amongst the sites. The Washington data shows a higher average accident frequency and a lower variability between sites compared to the original Minnesota data. Table 3. Accident Summary Statistics for Type I Sites
1 Vogt and Bared, 1998, (p. 60) 2 N/A: not available Total Accident ModelThe model was recalibrated with the additional years of accident data for the original Minnesota sites. Recall that the intersection related variable for vertical curvature, VCI1, did not exactly match those statistics given in the report. The parameter estimates, their standard errors, and p-values are provided in table 4, which reveals differences in the parameter estimates of the variables between the two time periods. VCI1 and RT were estimated with opposite signs to the original models, although in the original calibration these parameter estimates had large standard errors and were not statistically significant. This indicates that variables with large standard errors compared to the parameter estimates should not be included in the model even if engineering "common sense" suggests that they should. The other parameters were estimated with the same sign as originally and in some cases similar magnitude and significance to the original models. The overdispersion parameter, K, was estimated with a similar magnitude. Table 4. Parameter Estimates for Type I Total Accident Model Using Additional Years of Data
1 Vogt and Bared, 1998, (p. 115) 2 K: Overdispersion value GOF measure comparisons are shown in table 5. The Pearson product-moment correlation coefficient was marginally higher for the original data than when the model based on that data were used to predict the additional years of data. The MPB is higher for the prediction of the additional years of data. The MADs per year are similar for the predictions for the two time periods. The MSPE per year squared is lower than the MSE per year squared. Table 5. Validation Statistics for Type I Total Accident Model Using Additional Years of Data
1 N/A: not available The model was also recalibrated with the Washington data. The parameter estimates, their standard errors, and p-values are provided in table 6, which reveals differences in the parameter estimates of the variables between the two locations. All parameters were estimated with the same sign as the original models, and in some cases with similar magnitude and significance. Notable exceptions are VCI1 and HAZRAT1 which were estimated with the same sign but with a large difference in magnitude. For VCI1 both the original and newly estimated parameters had large standard errors. For the new Washington data HAZRAT1 had a large standard error and the overdispersion parameter, K, was higher than the original Minnesota model. A comparison of validation measures for the model recalibrated with the original data and the original model applied to the Washington data is shown in table 7. The Pearson product-moment correlation coefficient was slightly higher for the original data as compared to Washington data. The MPB, mean absolute deviations and mean squared prediction errors were similar in magnitude. Table 6. Parameter Estimates for Type I Total Accident Model Using Washington Data
1 Vogt and Bared, 1998, (p. 115) 2 K: Overdispersion value Table 7. Validation Statistics for Type I Total Accident Model Using Washington Data
1 N/A: not available Injury Accident ModelTable 8 shows the parameter estimates for the type I injury accident model using additional years of data. VCI1, RT MAJ, and HAUHAUHa were estimated with opposite signs than the original model, but this is not surprising when the large standard errors are considered. The other parameters were estimated with the same direction of effect, and in some cases similar magnitude and significance as the original model. The overdispersion parameter, K, was estimated to be slightly higher than that in the original model. Table 8. Parameter Estimates for Type I Injury Accident Model Using Additional Years of Data
1 Vogt and Bared, 1998, (p. 116) 2 K: Overdispersion value Validation statistics are shown in table 9 for the additional years of injury accident data. Since the original injury accident counts were not obtained these measures are not provided for the original years. The Pearson product-moment correlation coefficient was lower (0.553) than that for total accidents (0.614 for the recalibrated model) and the MAD per year (0.106) was about one half of that for total accidents. The model was also recalibrated with the Washington data. The parameter estimates, their standard errors, and p-values are provided in table 10, which reveals differences in the parameter estimates of the variables between the two States. Table 9. Validation Statistics for Type I Injury Accident Model Using Additional Years of Data
Table 10. Parameter Estimates for Type I Injury Accident Model Using Washington Data
1 Vogt and Bared, 1998, (p. 116) 2 K: Overdispersion value The parameters were all estimated with the same sign but in several cases the difference in magnitude was large. The overdispersion parameter, K, was estimated with a similar magnitude. Validation measures for the Washington data are shown in table 11. The Pearson product-moment correlation coefficient was lower (0.505) than that for total (0.579) accidents, and the MADs per year are about one half that for total accidents. Table 11. Validation Statistics for Type I Injury Accident Model Using Washington Data
2.4.2 Model IIThe summary statistics shown in table 12 indicate that there is little difference in the mean accident frequencies between original (1985-89) and additional (1990-98) years for the Minnesota sites, although there is more variation in the latter data. The Washington sites exhibit a large increase in the mean accident frequency and a larger variability between sites. Total Accident ModelThe model was recalibrated with the additional years of accident data for the Minnesota sites. Recall that the intersection related variables did not exactly match those statistics given in the report. The parameter estimates, their standard errors, and p-values are provided in table 13, which reveals differences in the parameter estimates of the variables between the two time periods. Table 12. Accident Summary Statistics for Type II Sites
1 Vogt and Bared, 1998, (p. 64) 2 N/A: not available The parameters were estimated with the same sign as the original model and in several cases with similar magnitude and significance. VCI1 and HAU were estimated with a large difference in magnitude. The overdispersion parameter, K, was almost twice as large as the original model. Table 13. Parameter Estimates for Type II Total Accident Model Using Additional Years of Data
1 Vogt and Bared, 1998, (p. 115) 2 K: Overdispersion value A comparison of validation measures for the original data additional years is shown in table 14. The Pearson product-moment correlation coefficient was higher for the original data than for the original model applied to the additional years. The MADs per year are similar. For the additional years model, the MSPE per year squared is higher than the MSE per year squared, indicating that the model is not performing as well on the additional years of data. Table 14. Validation Statistics for Type II Total Accident Model Using Additional Years of Data
1 N/A: not available The model was also recalibrated with the Washington data. The parameter estimates, their standard errors, and p-values are provided in table 15, which reveals differences in the parameter estimates of the variables between the two States. HI1, VCI1, and HAU were estimated with opposite signs, which might be expected on the basis of the large standard errors both in the original model and the model estimated using Washington data. Again, this would seem to indicate that variables with large standard errors in the parameter estimates should not be included in the model even if engineering common sense suggests they should. The other parameters were estimated with the same sign but with generally large differences in magnitude. The overdispersion parameter, K, was estimated to be over three times as large as that for the original model. Table 15. Parameter Estimates for Type II Total Accident Model Using Washington Data
1 Vogt and Bared, 1998, (p. 115) 2 K: Overdispersion value A comparison of validation measures for the original data and the original model applied to the Washington data is shown in table 16. The Pearson product-moment correlation coefficient was higher for the original data as compared to the Washington data. The MAD per year is much higher for the Washington data, indicating that the model is not performing well on these data. Table 16. Validation Statistics for Type II Total Accident Model Using Washington Data
Injury Accident ModelFor the injury accident model, the parameter estimates, their standard errors, and p-values are provided in table 17. HAU was estimated with the opposite sign to the original model and with a large standard error. The other variables were estimated with the same sign as the original model, but in some cases with large differences in magnitude. The overdispersion parameter, K, was estimated to be more than twice that of the original model. Table 17. Parameter Estimates for Type II Injury Accident Model Using Additional Years of Data
1 Vogt and Bared, 1998, (p. 117) 2 K: Overdispersion value Validation measures for the additional years of data are provided in table 18. Because the original injury accident counts were not obtained these measures are not provided for the original years. The Pearson product-moment correlation coefficient was lower (0.671) than that for total accidents (0.668), and the MAD per year is about twice that for total accidents. Table 18. Validation Statistics for Type II Injury Accident Model Using Additional Years of Data
The model was also recalibrated with the Washington data. The parameter estimates, their standard errors, and p-values are provided in table 19, which reveals differences in the parameter estimates of the variables between the two States. HI1, RT MAJ, and HAU were estimated with opposite signs and large differences in magnitude compared to the original estimates. The other variables were estimated with the same sign but with generally large differences in magnitude. The overdispersion parameter, K, was estimated to be more than three times that of the original model. Table 20 shows the validation statistics for the original injury accident model applied to the Washington data. The Pearson product-moment correlation coefficient was lower (0.482) than that for total accidents (0.517) and the MADs per year are about sixty percent of that for total accidents. Table 19. Parameter Estimates for Type II Injury Accident Model Using Washington Data
1 Vogt and Bared, 1998, (p. 117) 2 K: Overdispersion value Table 20. Validation Statistics for Type II Injury Accident Model Using Washington Data
2.4.3 Model IIIThe summary statistics shown in table 21 indicate that there are differences in the accident frequencies between the original (1993-95) and additional (1996-97) years. Note that the statistics compare 3 years of accident data in the original data to 2 years of accident data for validation using the additional years of data. For example, the means per year of TOTACC and TOTACCI for 1993-95 are 1.29 and 0.87, respectively. The means per year of TOTACC and TOTACCI for 1996-97 are 0.75 and 0.62, respectively. Note that the 1993-95 data for the original INJACC and INJACCI models could not be obtained. Table 21. Accident Summary Statistics of Type III Sites
1 Vogt, 1999, (p. 53) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||