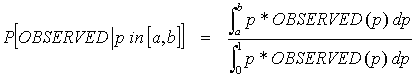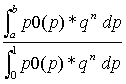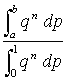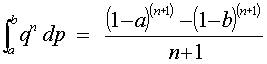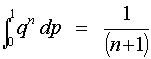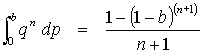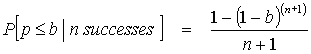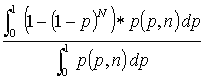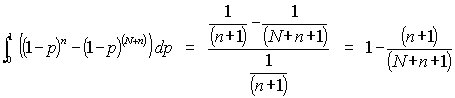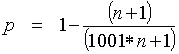U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-04-080
Date: September 2004 |
||||||||||||||||||||||||||||||||
Software Reliability: A Federal Highway Administration Preliminary HandbookPDF Version (697 KB)
PDF files can be viewed with the Acrobat® Reader® Chapter 4: Safe Introduction of Software Using Scale UpWhile software systems can contain millions of different computational paths, most are probably tested with orders of magnitude fewer test runs. This means that there may be potential failures lurking in the large population of situations that are never encountered during testing. For software that is embedded in safety critical systems, some software failures are deadly, as illustrated by the Therac-25 accidents. This page shows a method for calculating the number of expected failures when scaling up from testing to application in those situations where no failures are observed during testing. The ProblemA safety critical program is to be run N times, where N is large, e.g., millions of times. It has been tested on a random sample of n data items from the population of production runs, where n is small, e.g., in the hundreds. No failures were observed. How many failures can be expected in a large number of runs? And how can we minimize the danger of failures? What Is Learned from "n" SuccessesThe binomial distribution is the probability distribution that describes the number of failures that will be observed in N trials, if the probability of failure on a single trial is p. When at least 5 successes and at least 5 failures are observed in a large number of runs (more than 30) the normal distribution can be used to approximate the binomial distribution. However, a system from which most bugs have been removed may not fail often enough during testing to use this approximation. In these cases, Bayes' Theorem can be used to analyze the rarely failing system. Bayes' Theorem provides a method for estimating the likelihood that a probability lays in a known interval, given a probability density function, OBSERVED(p), depending on p for what was observed. p has some, if unknown, value. The probability of observing OBSERVED if p is in some small interval, dp, is the probability of the joint event that p is in the interval times the probability of OBSERVED, given p in the interval. The probability that p is in dp is p*dp, so observing OBSERVED given p in [a,b] is proportional to:
Dividing (1) by the probability of OBSERVED for p in [0,1]
insures that the probability of observing OBSERVED for some p is 1; this gives Bayes' Theorem,
Given a failure probability p (which is not known), the joint distribution of 0 failures in n trials is qn, where q = 1-p.
Before the program has been run, it is hoped that p is small, but not known, so that all prior probabilities can be assumed to be equally likely, and (4) becomes
Since
And
Consequently,
ExtensionsThe same derivation of equation (9) applies when a small number of failures are observed. In that case, the probability density function of what was observed contains the last few terms of the binomial distribution. For example, if one failure is observed, the density function, to be integrated in Bayes' Theorem, is:
where p is the probability of failure, and q = 1-p is the probability of success. When there are more than five failures, the normal approximation can be used. ApplicationsHolding Failures to a Low LevelSuppose that n trials are run with 0 failures, and it is desired that failures be kept less than K. How many runs can be made? For the initial analysis, we will ask what the expected number of 0 failures is as the number of runs increases. Given a failure probability p, if N runs are made, the probability of 0 failures is (1-p)N. Then the probability of one or more failures is:
where p(p,n) is the probability of p being the true probability after making n runs and observing 0 failures. With uniform prior probability before the n runs, this is:
So the probability of one or more failures is:
Example: Holding failures to a low level.If we have run n tests and want to keep the probability of one or more failures <0.5, then:
So
Example: Big increase in the number of runs.Suppose N = 1000 * n. Then:
Which is approximately 0.999. In other words, the chance of observing a failure is close to 1 when the number of actual runs is 1000 times greater than the number of test runs. ConclusionTo prevent failures when a system is introduced, the deployment should be done in a succession of phases. In each phase, the number of deployments is a multiple of the deployments in the previous phase. The system is observed in the larger deployment, and this result is used as the test run in the next phase of the deployment. |