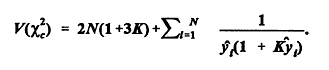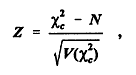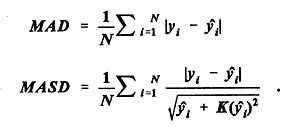U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-98-133
Date: October 1998 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Accident Models for Two-Lane Rural Roads: Segment and Intersections6. Validation and Further AnalysisValidation Validation Techniques The chi-square statistic
A more refined approach is to compute the z-score of the concocted statistic
Then the z-score of
and this statistic is approximately normal. Also computed are the mean absolute deviation (MAD) and the mean absolute scaled deviation (MASD):
These are two additional measures of the predictive power of the model. Minnesota Models versus Later Minnesota Data Highway Safety Information System data became available during the course of this study for the years 1990-1993 in Minnesota. These data included accident counts, traffic, shoulder widths, lane widths, and speeds for 392 segments (out of the 619 in the original sample), and accident, traffic, and speed data for 365 three-legged intersections (out of the original 389) and 309 four-legged intersections (out of the original 327). The sample sizes for the second time period are smaller because sites with major changes (for example, segments that had changed length) or for which accident counts were not available were omitted. The new values of the highway variables were applied to the leading models and the predicted mean accident counts were compared with actual accident counts to test how the models performed. Variables such as number of driveways, Roadside Hazard Rating, and alignment were not revised for the new data sets. The values of these variables were obtained from photologs for 1985-89 and original construction plans. Updated values were not available, and it was assumed that few changes had occurred. Table 41 shows the results of applying the Minnesota models from Tables 26 and 35 to the 1990-93 Minnesota data. The first model is an extended negative binomial model for segments
with an overdispersion parameter K = .2722, the second and third models are negative binomial models with K = .4811 and .2055, respectively. The critical value
Table 41. Validation of Minnesota Models with 1990-1993 Minnesota Data
* One outlier removed Nonetheless, in other respects the fits are reasonably good, not only for the segments but also for the intersections, with small mean absolute and absolute scaled deviations. The four-legged intersections improve dramatically when one outlier is removed, an intersection with 51 accidents in 1990-1993. The objection may be made that accidents in the new time period are correlated with accidents in the old time period, and that the validation sample is not independent of the sample used to derive the model. The effect of this might be to generate predicted accident counts for the new time period similar to those in the old time period, but with the dependency on highway variables not receiving a genuinely independent test. Indeed, the overfitting of the segment data suggests this possibility. Minnesota Models versus Washington Data Table 42 below shows validation results when the Minnesota models of Table 41 are applied to the Washington segments and intersections. In this case there is no danger of correlation and the validation data serve as an independent sample.
Table 42. Validation of Minnesota Models with 1993-1995 Washington Data
Table 42 shows a marked difference between the segment and four-legged Minnesota models and the corresponding Washington data with respect to In the case of the segments one explanation of the large z-score of i) the model is used as is; ii) the predicted mean is taken to be that in i), multiplied by the ratio (1.0228/.6656) of the accident rate (accidents per million vehicle-miles) in Washington to the accident rate in Minnesota; or iii) the predicted mean is taken to be that in i) multiplied by that factor which gives the maximum likelihood estimate when the predicted mean in i) is used as an offset.
Table 43. Validation of Adjusted MN Segment Model with 1993-1995 WA Data
Table 43 shows that multipliers lead to better fits. An argument in favor of the maximum likelihood multiplier, exp(.0914), is that the ratio of the overall accident rates, 1.0228/.6656 = exp(.430), does not measure the effect of variables besides exposure observation by observation and that differences between the two States in these other variables may already be represented in the model. Method iii) introduces the intercept giving the maximum likelihood fit after the model has accounted for other variables to the extent possible. Table 43 calls attention to the important question of how a model developed for one or more States in some time period should be applied to other States and/or other time periods. A multiplier such as the ratio of accident rates or the maximum likelihood intercept can be applied, or even one tailored to minimize Washington and Combined Segment Models versus Minnesota Data Table 44, similar to Table 43, can be generated by applying a Washington State segment model to
the Minnesota data. The extended negative binomial model for Washington State from Table 26 is applied to the 1985-1989 Minnesota data with and without a multiplier in Table 44. The ratio of accident rates, .6656/1.0228 = exp(-.430), yields the largest z-score for
Table 44. Validation of Adjusted WA Segment Model with 1985-1989 MN Data
The combined extended negative binomial model for segments (Table 27) can be applied to the segment data for Minnesota and Washington individually and, as expected, yields z-scores for The data used for validation in Table 45 are not independent of those used in modeling since some of the segments are the same. Nonetheless, it is of interest to note that adjustments may be appropriate when a model is applied to a new time period. Table 45 shows that adjustments that increase likelihood may have variable effects on
Table 45. Validation of Combined Segment Model with 1990-1993 MN Data
|