U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-05-079
Date: May 2006 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
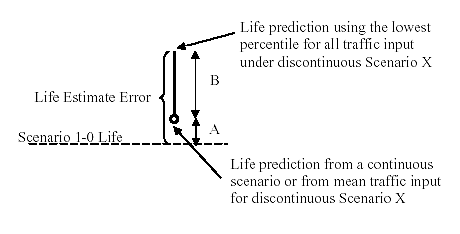
Optimization of Traffic Data Collection for Specific Pavement Design ApplicationsChapter 6. Define Traffic Collection RequirementsFrom a pavement design point of view, traffic data collection requirements need to be established as a function of the tolerable error and the desirable confidence in NCHRP 1-37A design guide life predictions. The error is defined as the difference between pavement life predictions obtained under a particular scenario and those obtained under true traffic (scenario 1-0). This error, expressed in percentage, was determined from the series of pavement life prediction plots presented in Appendix D. It comprises two components, as shown schematically in figure 17, which are labeled as "A" and "B." "A" is the estimated error from the traffic input of a continuous scenario or the mean traffic input of a discontinuous time-coverage scenario. "B" is the additional error possible in discontinuous-coverage scenarios by considering the lowest percentile input for all traffic input estimates simultaneously. Although doing so is very conservative, it allows establishment of the statistical maximum error in predicting pavement life, and therefore, it answers the question of reliability, as explained earlier. Figure 17. Components of the percentage difference between pavement life predictions for scenario X and those for scenario 1-0.
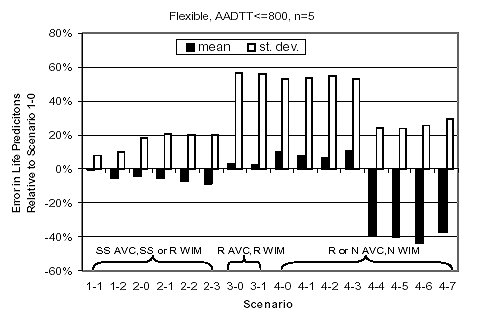
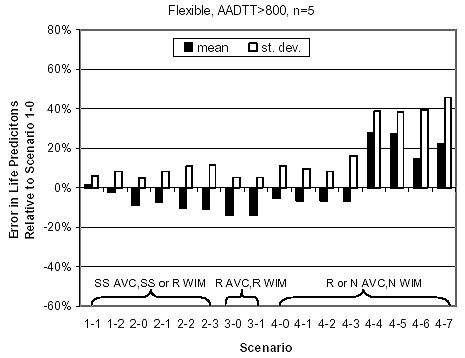
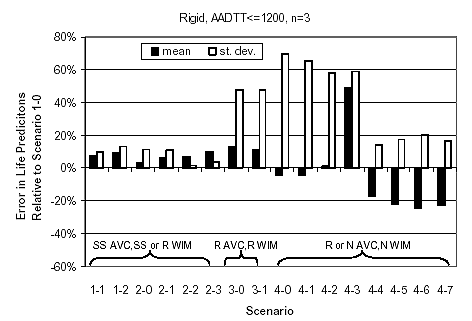
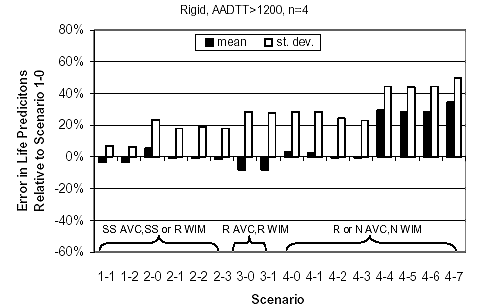
Statistics for quantity "A" were computed by scenario type using the NCHRP 1-37A design guide performance predictions for the sites analyzed. These results are plotted by pavement type and traffic level in figures 18 through 21. In interpreting these results, consideration was given to the source of traffic input for each scenario, as outlined in table 22. To facilitate interpretation, the scenarios in these figures were arranged in three groups:
Analysis of figures 18 through 21 reveals the following information:
Statistics for pavement prediction error component "A" were computed for all 17 sites analyzed (table 29). Indeed, the mean values of this error component are negligible. Ranges in these errors were estimated as a function of the selected level of confidence (i.e., 100 percent minus the probability of exceeding that error), assuming that the mean error values are zero. Because the sample size is small, the Student's t-standard deviate was used. The values corresponding to one-sided probabilities of 75 percent, 85 percent, and 95 percent for 17 observations are 0.69, 1.07, and 1.74, respectively. The error ranges obtained as a function of the probability of exceeding them are listed in table 29 and plotted in figure 22. Figure 18. Statistics for error component "A" in life predictions (percent), flexible pavement sites with AADTT = 800 trucks/day/lane.
Figure 19. Statistics for error component "A" in life predictions (percentage), flexible pavement sites with AADTT > 800 trucks/day/lane.
Figure 20. Statistics for error component "A" in life predictions (percentage), rigid pavement sites with AADTT = 1,200 trucks/day/lane.
Figure 21. Statistics for error component "A" in life predictions (percentage), rigid pavement sites with AADTT > 1,200 trucks/day/lane.
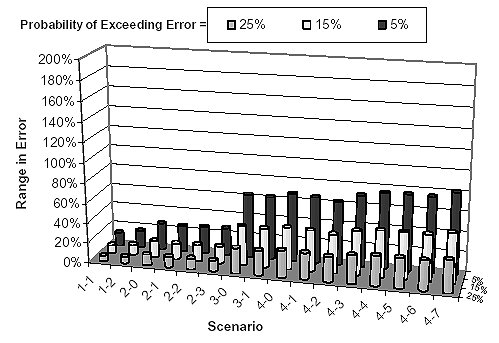
Figure 22. Estimated range in NCHRP 1-37A design guide pavement life prediction errors from mean traffic input.
Assuming mean traffic input, figure 22 can be used to establish the least effort traffic data collection scenario that will provide a maximum acceptable pavement life prediction error under a selected level of confidence. For example, scenarios 3-0, 3-1, and 4-2 are among the least effort scenarios capable of a 25-percent maximum error in predicting pavement life (e.g., 3.5 years in a 14-year design period) with a 75-percent confidence. A better traffic data collection scenario would be needed to either decrease the level of the acceptable error or increase the confidence that it will not be exceeded. The error ranges described above were obtained assuming mean
traffic input for each discontinuous traffic data collection
scenario. Additional errors were computed because of the variation
in traffic input resulting from the sampling scheme used within
each of the traffic data collection scenarios that involved
discontinuous time coverage. These reflect the error component "B"
defined in figure 17. As described earlier, this error component in
predicting pavement life was computed from the NCHRP 1-37A design
guide life estimates obtained by inputting the low percentile for
all of the traffic elements simultaneously. Table 30 shows the mean
and the standard deviation of these errors by traffic input
percentile level. It also shows the standard deviation in the mean
errors computed by dividing the standard deviation of the errors by
the square root of the number of degrees of freedom (i.e.,
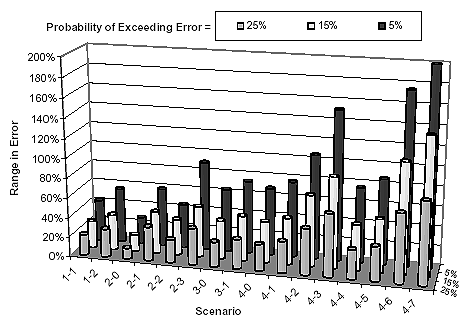
The combined range in the two error components "A" and "B" was computed by percentile level by adding the range in the error component "A" to the range in the mean of the error of component "B." The results are shown in table 32 and plotted in figure 23. Figure 23 was compiled assuming that the lowest percentile of all of the traffic input for a discontinuous-coverage scenario could be input simultaneously during design. As mentioned earlier, this is very conservative; however, it addresses the question of reliability to guarantee the designer that a particular error level will not be exceeded given a level of confidence. Assuming low-percentile traffic input, figure 23 can be used to establish the least-effort traffic data collection scenario that will provide a maximum acceptable pavement life prediction error under a selected level of confidence. Compared to the earlier example, scenario 3-0 is the only one among the least effort scenarios identified earlier capable of a 25-percent minimum error in predicting pavement life with a 75-percent confidence. A better traffic data collection scenario would be needed to either decrease the level of the acceptable error or increase the confidence that it will not be exceeded. The main observations drawn from figure 23 are summarized below:
Figure 23. Estimated range in NCHRP 1-37A design guide pavement life prediction errors from low-percentile traffic input.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||