U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-HRT-05-079
Date: May 2006 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Optimization of Traffic Data Collection for Specific Pavement Design ApplicationsChapter 3. Define Traffic Data Collection Requirements For Each Selected ApplicationTraffic data collection requirements were based on the four levels of traffic monitoring technology defined in table 4 of this report based on Appendix A of the final NCHRP 1-37A report.(1) Distinct scenarios were developed by defining the length of data coverage of the site-specific data. Seventeen traffic-sampling scenarios were selected, as shown in table 8, where SS denotes site-specific, R denotes regional, and N denotes national data. The third column of this table, highlighted by bold letters, specifies the time coverage of the site-specific data. The fourth column provides identification codes for these scenarios, consisting of two numbers separated by a dash; the first number indicates the NCHRP 1-37A design guide traffic input level, and the second number identifies the length of data coverage (e.g., scenario 2-1 signifies site-specific AVC data with a coverage of 1 month in each of 4 seasons plus regional WIM data). In selecting these scenarios, the following two main criteria were adhered to:
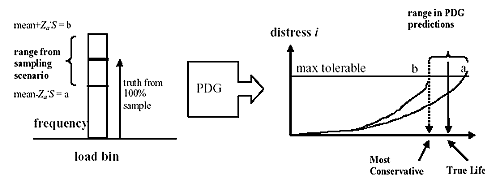
SS = Site-specific, R = Regional, N = National (NCHRP 1-37A design guide defaults) As described later, representative regional (R) traffic input can be obtained by averaging data from sites with similar traffic characteristics. There are a variety of methods for establishing similarities in traffic characteristics, ranging from the purely subjective (e.g., same roadway functional class) to the fairly mathematical (e.g., clustering techniques).(3,17) The clustering approach was selected for identifying similarities between the LTPP sites selected for the detailed NCHRP 1-37A design guide analysis and the remaining extended-coverage LTPP sites. Similarities were established on the basis of vehicle classification distributions and tandem-axle load distributions. The average traffic element for each cluster defined the regional data input for each site. In simulating these scenarios, the default values provided in the NCHRP 1-37A design guide software were assumed to represent the national (N) traffic input. For each of these traffic data collection scenarios, the range in the traffic input elements to the NCHRP 1-37A design guide (table 3) are computed and the resulting range in pavement performance predictions by distress are estimated. This process is shown schematically in figure 1, where S symbolizes the standard deviation in a particular traffic data input element, in this case, load frequency, and Za is the standard normal deviate (i.e., values for Za will be selected in accordance to the desired reliability level as per table 9). For each sampling scenario and reliability level selected, the range in pavement life predictions by distress mechanism is obtained using the software for the NCHRP 1-37A design guide. Figure 1. Schematic of the sensitivity of distress predictions to load spectra input.
This type of sensitivity analysis will be conducted for both flexible and rigid pavements under realistic structural conditions. This involves site-specific layer thicknesses as described in the LTPP database and environmental conditions as simulated by the NCHRP 1-37A design guide software. Layer moduli were specified in the same fashion for all sites simulated in order to keep the variation in nontraffic-related properties to a minimum. Incidentally, another study is needed to establish the sensitivity of the NCHRP 1-37A design guide design process to variations in layer properties, considering the traffic input as a constant. This would ensure that groups of input with comparable accuracy would be used in pavement design.
|