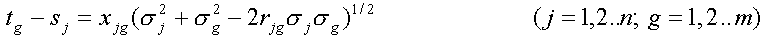U.S. Department of Transportation
Federal Highway Administration
1200 New Jersey Avenue, SE
Washington, DC 20590
202-366-4000
Federal Highway Administration Research and Technology
Coordinating, Developing, and Delivering Highway Transportation Innovations
 |
| This report is an archived publication and may contain dated technical, contact, and link information |
|
Publication Number: FHWA-RD-03-065
Date: September 2004 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In-Vehicle Display Icons and Other Information Elements: Volume IPDF Version (8.33 MB)
PDF files can be viewed with the Acrobat® Reader® CHAPTER 9: TUTORIALSTUTORIAL 1: ANALYSIS OF RANK ORDER DATAIn this tutorial, we describe the types of information that can be obtained from rank-order data. We assume that the data is collected in the following manner. A total of nj judges are asked to rank order ns stimuli (e.g., icons) with respect to some attribute (e.g., appropriateness for a specific message). Usually the whole set of stimuli is presented together, and the judges are allowed to proceed as they wish as long as each judge comes through with a single rank order along the attribute specified. If many stimuli are presented, it might be useful for the judges to sort them roughly into grades before attempting the final ranking. A hypothetical data set is presented in table 9-1. These hypothetical data might be obtained from 10 individuals who rank ordered 5 icons (icons A, B, C, D, and E) in appropriateness for a specific message. The icons would be assigned ranks of 1-5, with "1" corresponding to the icon considered to be the most appropriate 1.
Table 9-1. Sample Data Set: Ranks Assigned to 5 Icons by 10 Judges Our goal is to investigate whether and how much the judged stimuli differ with respect to the attribute of interest. This goal can be accomplished at different levels using different methods of analysis. In the following sections, we discuss some of these methods. First, we indicate a quick way to determine a composite rank order for the stimuli. Second, we discuss the use of mean ranks. Third, we outline two methods of obtaining scores for the stimuli on an interval scale. In addition to a general rank ordering, these scores provide an indication of relative differences among the stimuli. Finally, we discuss the use of more advanced and complex statistical methods that allow us to test whether the stimuli are truly different with respect to the attribute of interest. 1. DERIVING RANK ORDER FROM SUMS OF ASSIGNED RANKSA composite ranking for the stimuli can be obtained by computing the sums of the rank values assigned to each of the stimulus. The order of the magnitudes of the sums will indicate an ordering of the stimuli, with the lowest sum corresponding to the stimulus judged as the best. For example, for the raw data of table 9-1, we obtain the sums presented in table 9-2, which indicate the following composite rank order from the most to least appropriate icon: C, B, D, A, and E. Table 9-2. A Composite Ranking of Icons Obtained from Sums of Assigned Ranks
2. OBTAINING MEAN RANKSMean ranks are obtained for each icon by dividing the sum of the ranks assigned to that icon by the number of judges. For example, for the raw data of table 9-1, the mean rank of icon A is 35/10 = 3.5. Mean ranks corresponding to all five icons in the sample data set are presented in table 9-3. In general, mean ranks will somewhat agree with the composite ranks in both order and spacing. Table 9-3. Mean Rank of Each of the Icons
It should be noted that mean ranks should never be used to judge the absolute differences between the stimuli. For example, on the basis of the data presented in table 9-3, we could not conclude that icon E was judged to be 1.5 times more inappropriate than icon A. At best, mean ranks provide an indication of relative differences. For example, mean ranks in table 9-3 indicate that the difference between icons B and A is the same as the difference between icon A and E. However, the reader should be warned that rank values are strictly ordinal numbers2 and there is little numerical meaning to be attached to means of such values. To obtain more precise relative differences between the stimuli, we recommend the use of the scaling methods discussed in the next section. 3. OBTAINING INTERVAL-SCALE VALUESAs mentioned above, rank data (i.e., the rank orders produced by the judges) are on an ordinal scale. This scale arranges things in order of magnitude, but does not reveal the magnitude of the differences between them. An interval scale, on the other hand, allows statements about how much difference there is between two objects. A good example for an interval scale is the Fahrenheit scale of temperature. Here, it is meaningful to say that there is as much difference between 60 °F and 70 °F as there is between 70°F and 80°F. Note, however, that interval-scale values are not absolute magnitudes. For instance, it is not accurate to say that 80°F is twice as high as 40°F. Using rank orders generated by a group of judges, it is possible to obtain interval-scale values for the ranked items. Below, we discuss two different methods of obtaining interval-scale values using rank order data: (1) Choice Score Method, and (2) Torgerson's Categorical Scaling Method. The reader should keep in mind that the values obtained using either of the scaling methods are not meaningful in absolute terms, but that they give only an indication of relative differences between the stimuli. As an example, let us assume that we have obtained scale values of 2.5, 5, and 7.5 for icons A, B, and C, respectively. Based on these values, we cannot conclude that icon A is three times as good (or appropriate) as icon C. However, we can say that there is as much difference between icons A and B as there is between B and C. Such information can be important to icon designers, who frequently must make tradeoffs among design issues such as cost, driver performance, and driver preferences. Converting the rank-order data to an interval scale allows for more systematic and rigorous tradeoff analyses to be conducted. A. Choice Score Method This scaling procedure, described in Engen (1971), converts rank orders to choice frequencies, then to p values, and finally to z scores (unit normal deviates). The z scores obtained represent scale values for the stimuli on a psychological scale with equal intervals on the assumption that the rankings are normally distributed. The procedure is outlined below; the computations for the sample data set are shown in table 9-4. Table 9-4. Computations for the Choice Score Method
* The following can be used to check the calculations: (1) mean Mr must be equal to (ns+1)/2; (2) mean choice (Mc) must be equal to (ns-1)/2; (3) mean p must be equal to 0.5. Step 1. Calculate the mean rank (Mr) assigned to each stimulus (see table 9-2). Step 2. Calculate a mean choice score (Mc) for each stimulus by subtracting the mean rank from the number of stimuli (ns). For example, the mean choice Mc score for icon A of the sample data set is 5 - 3.5 = 1.5. Step 3. Convert the mean choice scores (Mc) into p values by dividing them by (ns - 1). For example, the p value for icon A of the sample data set is 1.5/4 = 0.38. The computations performed so far can be checked with the following:
For example, in table 9-4,
Step 4. Convert the p values into z scores using table 9-5. The z scores obtained in step 4 represent scores for the stimuli on an interval scale. Because the z values are generally awkward numbers to use, we recommend a linear transformation of the z values to a more convenient range as explained in step 5 below. (This transformation is similar to converting °F temperature to °C temperature.) Step 5. (Optional) Obtain a linear transformation of the z scores (i.e., multiply the z scores by a constant and add a constant). In table 9-4, we arbitrarily use the transformation R = 5z + 6; any other linear transformation (e.g., R = 2z + 1) can be used. The purpose of this transformation is to obtain scores in a more convenient range than the z scores obtained in step 4. The R values, like the z values obtained in step 4, represent interval-scale values for the stimuli, with higher values indicating stimuli judged to be better with respect to the attribute of interest. As seen in table 9-4, icon E cannot be assigned a scale value. This results from the fact that icon E was invariably placed in ranked 5. If a stimulus is placed in the same rank by all judges, it cannot be assigned a scale value using this procedure. Table 9-5. p-z Conversation Table
B. Torgerson's Categorical Scaling MethodThis scaling method is based on Torgerson's Law of Categorical Judgment. (Torgerson, 1962). While it involves more computational steps than the Choice Score Method, it also seems to reflect stronger theoretical foundations. For the raw data of table 9-1, the two scaling methods produce similar scores; however, we cannot conclude that the scale values will be the same in all cases. This method is as follows:
Step 8. Compute interval-scale values for the stimuli by listing the stimuli in the same order as in matrix F, assigning a score of 0 to the last stimulus in the list, and cumulating toward the top using the row means of matrix G. For matrix G of table 9-12, the scale values are computed as shown in table 9-13. The first column lists the icons in the same order they were listed in matrix F of table 9-11; the second column lists the row means of matrix G of table 9-12. We first assign a scale value of 0 to icon A. We then compute the scale value of icon D as follows: 0+0.77 = 0.77. Scale values for icons B and C are assigned in a similar manner. Table 9-13. Step 8: Assigning Interval-Scale Values
Note that higher scale values indicate better (i.e., more appropriate) icons. Note also that we cannot assign a scale value for icon E, but we know that its score would be lower than the scores of all other icons, as it was placed in rank 5 by all judges. 4. CONDUCTING A TEST OF SIGNIFICANCEUsing the methods discussed so far, we might obtain a composite rank order for the stimuli with no ties, and a different interval-scale score for each stimulus. Does that mean that the stimuli are truly different from each other with respect to the attribute of interest? Not necessarily. To answer this question, we need to perform a test of significance. A test of significance allows us to determine, with a specified risk of error, whether the observed difference is really meaningful, or whether we might expect the same difference to occur merely because of chance factors. On rank-order data from a group of judges (e.g., the raw data of table 9-1), we can conduct a significance test based on Friedman Rank Sums to determine whether there are or are not real differences between the stimuli. A detailed explanation of this statistical test is beyond the scope of this tutorial, but the general outline is as follows:
Using the Friedman test, we can test the equivalence of all stimuli, or perform pairwise comparisons. For a detailed explanation of this statistical test, readers should refer to a text on nonparametric statistical methods (e.g., Hollander & Wolfe, 1973). The Friedman test is also available in several commercial statistical software packages. SUMMARYWe have discussed several methods of analyzing rank order data. These are summarized in table 9-14. This table provides a guide for the designer in determining which method(s) would be appropriate for the design problem at hand. Table 9-14. Summry of Methods Discussed for Analyzing Rank Order Data
References:
TUTORIAL 2: PROVIDING SUBJECTS WITH CONTEXT DURING ICON EVALUATIONSThis tutorial provides some guidance and examples of ways to provide appropriate context to experimental subjects during comprehension evaluations of candidate icons. In real-world driving, icons are presented in the context of certain in-vehicle capabilities and driving circumstances. As such, evaluations of in-vehicle icons should include a description of the context in which icons will be presented and used. However, icon evaluations should avoid providing either too little or too much context to experimental subjects. If too little context is provided, unrealistically low comprehension scores may result because the subjects may be unable to connect a visual icon with the many possible icon meanings. If too much context is provided, unrealistically high comprehension scores may result because the subjects have been cued for a certain response by the specificity of the context. Both these extremes should be avoided. The context provided to subjects should describe the: (1) general capabilities of the in-vehicle system that will be used to present the icons and (2) general driving circumstances associated with the presentation of the icon by the in-vehicle system. For example, an evaluation of an icon intended to warn drivers of a problem with the passive restraint system on their vehicle might provide the following "system capabilities" information to subjects:
The following " driving circumstances" information could be provided to drivers:
You have just started your car. A group of icons appears on your In-Vehicle Information System, including this icon. What do you think this icon means? Similarly, in the context of evaluating comprehension for a specific Motorists Services icon, the following "driving circumstances" information could be provided:
Figure 9-2. Motorists Services Icon You are driving on a highway. This icon appears on the In-Vehicle Information System installed in your car. What do you think this icon means? |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||